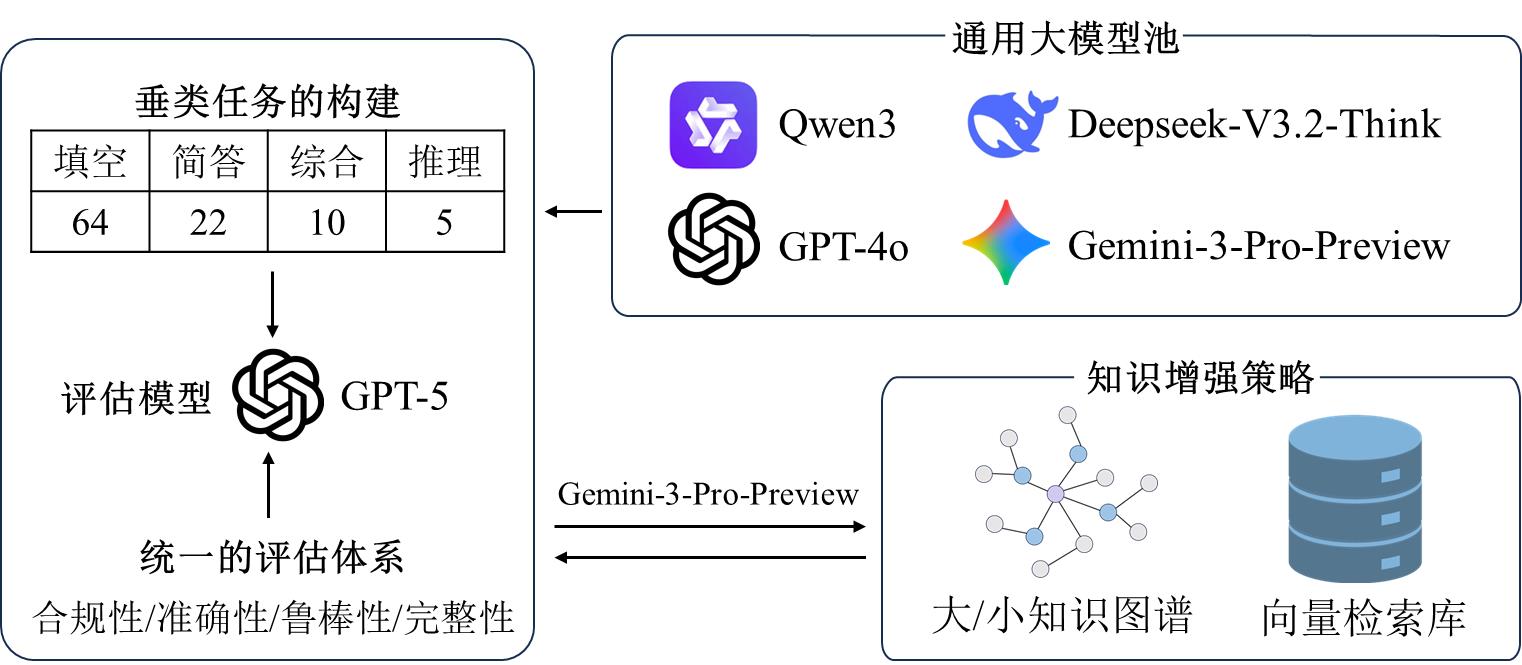
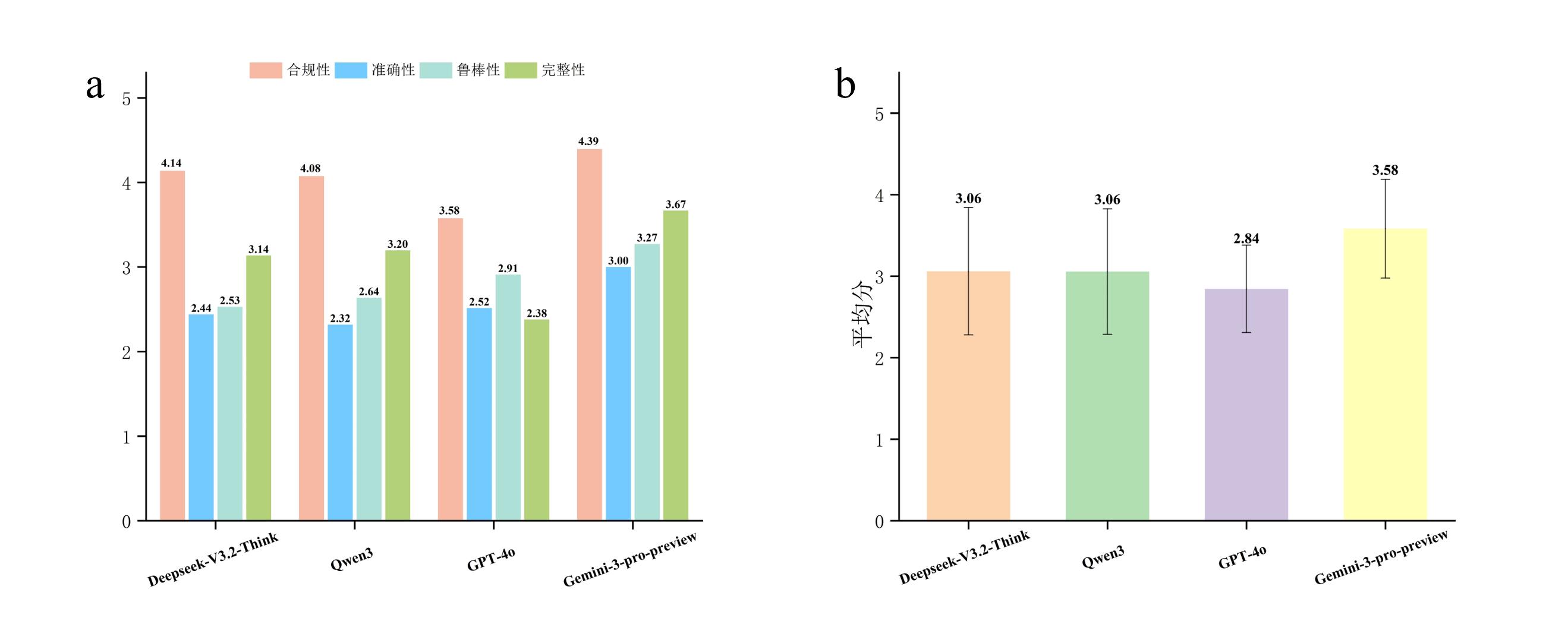
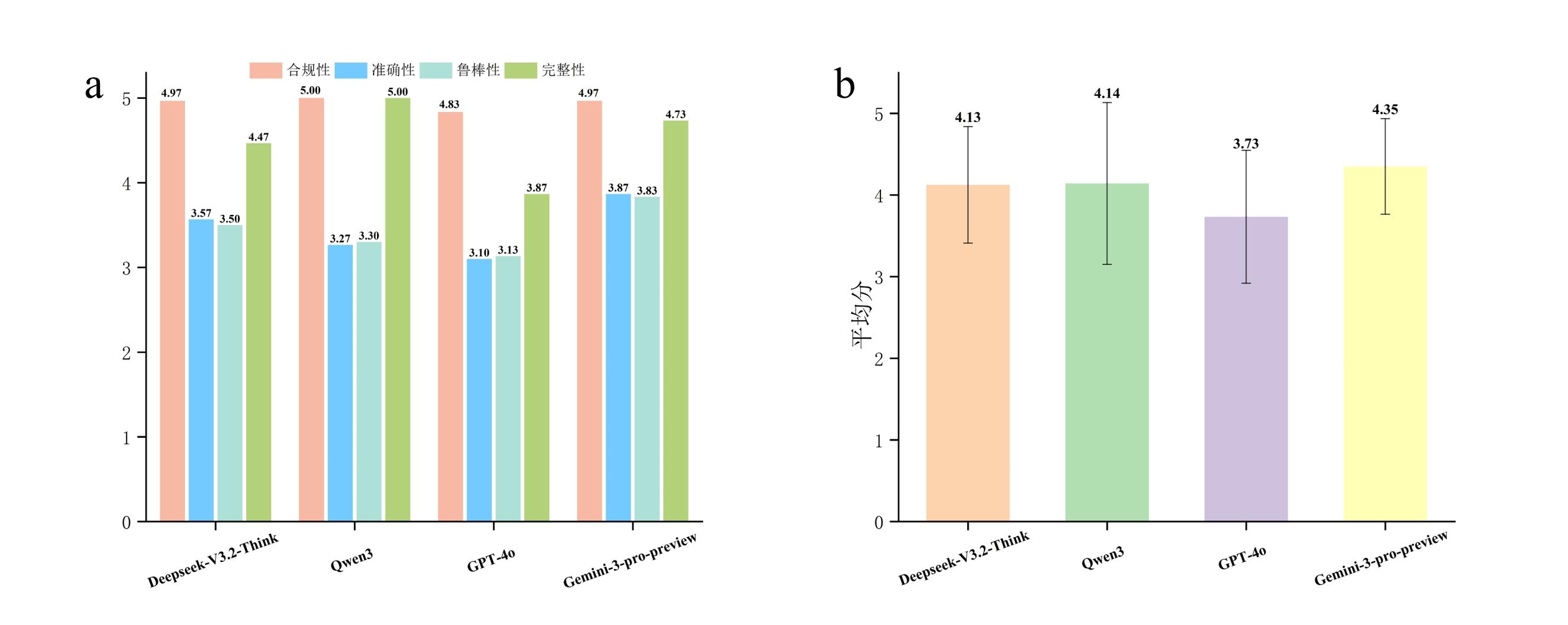
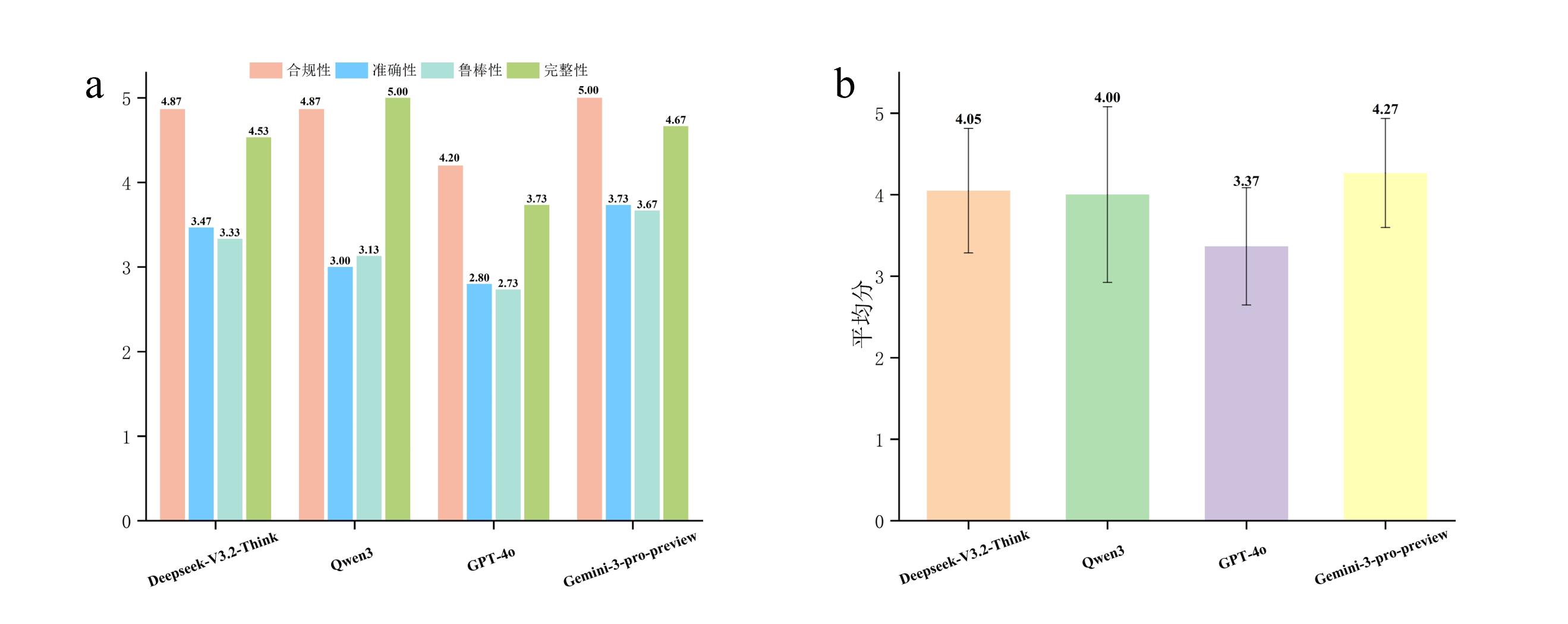
| [4] |
Choi J, Kim S, Jung Y. Synthesis-aware materials redesign via large language models[J]. Journal of the American Chemical Society, 2025, 147(43): 39113-39122.
|
| [5] |
Ma Q Y, Zhou Y H, Li J F. Automated retrosynthesis planning of macromolecules using large language models and knowledge graphs[J]. Macromolecular Rapid Communications, 2025: e2500065.
|
| [6] |
Fu F, Li Q Q, Wang F R, et al. Synergizing a knowledge graph and large language model for relay catalysis pathway recommendation[J]. National Science Review, 2025, 12(8): nwaf271.
|
| [7] |
Chen Z Y, Xie F K, Wan M, et al. MatChat: a large language model and application service platform for materials science[J]. Chinese Physics B, 2023, 32(11): 118104.
|
| [8] |
Chithrananda S, Grand G, Ramsundar B. ChemBERTa: large-scale self-supervised pretraining for molecular property prediction[EB/OL]. 2020: arXiv: 2010.09885.
|
| [9] |
Zhang D, Liu W, Tan Q, et al. ChemLLM: a chemical large language model[EB/OL]. 2024: arXiv: 2402.06852.
|
| [10] |
Weininger D. SMILES, a chemical language and information system. 1. Introduction to methodology and encoding rules[J]. Journal of Chemical Information and Computer Sciences, 1988, 28(1): 31-36.
|
| [11] |
Krenn M, Häse F, Nigam A, et al. Self-referencing embedded strings (SELFIES): a 100% robust molecular string representation[J]. Machine Learning: Science and Technology, 2020, 1(4): 045024.
|
| [12] |
Hastedt F, Bailey R M, Hellgardt K, et al. Investigating the reliability and interpretability of machine learning frameworks for chemical retrosynthesis[J]. Digital Discovery, 2024, 3(6): 1194-1212.
|
| [13] |
Xu Z W, Jain S, Kankanhalli M. Hallucination is inevitable: an innate limitation of large language models[EB/OL]. 2024: arXiv: 2401.11817.
|
| [14] |
Mirza A, Alampara N, Kunchapu S, et al. A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists[J]. Nature Chemistry, 2025, 17(7): 1027-1034.
|
| [15] |
Bran A M, Cox S, Schilter O, et al. Augmenting large language models with chemistry tools[J]. Nature Machine Intelligence, 2024, 6(5): 525-535.
|
| [16] |
Bai X F, He S, Li Y, et al. Construction of a knowledge graph for framework material enabled by large language models and its application[J]. npj Computational Materials, 2025, 11: 51.
|
| [17] |
Lewis P, Perez E, Piktus A, et al. Retrieval-augmented generation for knowledge-intensive NLP tasks[EB/OL]. 2020: arXiv: 2005.11401.
|
| [18] |
Liu B Y, Huang N, Wang Y, et al. Regioselectivity regulation of styrene hydroformylation over Rh-based Phosphides: Combination of DFT calculations and kinetic studies[J]. Chemical Engineering Journal, 2022, 441: 136101.
|
| [19] |
孙嘉辰, 张晓昕, 张涛, 等. 非均相Rh基烯烃氢甲酰化反应催化剂研究进展[J]. 应用化工, 2025, 54(8): 2170-2175.
|
|
Sun J C, Zhang X X, Zhang T, et al. Recent development towards heterogeneous hydroformylation of alkenes by Rh-based catalysts[J]. Applied Chemical Industry, 2025, 54(8): 2170-2175.
|
| [20] |
Gillum M, Ariyaratne G K P A, Tawny C, et al. Recent advances in heterogeneous hydroformylation at metal–oxide interfaces[J]. Molecules, 2025, 30(20): 4078.
|
| [21] |
Samanta P, Canivet J. MOF-supported heterogeneous catalysts for hydroformylation reactions: a minireview[J]. ChemCatChem, 2024, 16(7): e202301435.
|
| [22] |
Wang T, Wang W L, Lyu Y, et al. Porous Rh/BINAP polymers as efficient heterogeneous catalysts for asymmetric hydroformylation of styrene: Enhanced enantioselectivity realized by flexible chiral nanopockets[J]. Chinese Journal of Catalysis, 2017, 38(4): 691-698.
|
| [23] |
Breit B, Breuninger D. Desymmetrizing hydroformylation with the aid of a planar chiral catalyst-directing group[J]. Journal of the American Chemical Society, 2004, 126(33): 10244-10245.
|
| [24] |
Zhu Y X, Zhang Y C, He D Y, et al. Rhodium-catalyzed asymmetric reductive hydroformylation of α-substituted enamides[J]. Journal of the American Chemical Society, 2024, 146(48): 33249-33257.
|
| [25] |
Sandmann S, Hegselmann S, Fujarski M, et al. Benchmark evaluation of DeepSeek large language models in clinical decision-making[J]. Nature Medicine, 2025, 31(8): 2546-2549.
|
| [26] |
DeepSeek-AI, Liu A X, Mei A X, et al. DeepSeek- V3.2: pushing the frontier of open large language models[EB/OL]. 2025: arXiv: 2512.02556.
|
| [27] |
Yang A, Li A F, Yang B S, et al. Qwen3 technical report[EB/OL]. 2025: arXiv: 2505.09388.
|
| [28] |
OpenAI,:, Hurst A, et al. GPT-4o system card[EB/OL]. 2024: arXiv: 2410.21276.
|
| [29] |
于婷, 刘英琦, 王恒飞, 等. 基于大语言模型的乏燃料后处理脉冲柱萃取过程预测[J]. 化工学报, 2025.
|
|
Yu T, Liu Y Q, Wang H F, et al. Prediction of the pulse column extraction process for spent fuel reprocessing based on large language models [J]. Journal of Chemical Industry and Engineering, 2025.
|
| [30] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[EB/OL]. 2017: arXiv: 1706.03762.
|
| [1] |
Walls B W, Linic S. Use of large language models for extracting and analyzing data from heterogeneous catalysis literature[J]. ACS Catalysis, 2025, 15(17): 14751-14763.
|
| [2] |
Kang Y, Lee W, Bae T, et al. Harnessing large language models to collect and analyze metal–organic framework property data set[J]. Journal of the American Chemical Society, 2025, 147(5): 3943-3958.
|
| [3] |
Dagdelen J, Dunn A, Lee S, et al. Structured information extraction from scientific text with large language models[J]. Nature Communications, 2024, 15: 1418.
|
 ), 许昊翔(
), 许昊翔( 京公网安备 11010102001995号
京公网安备 11010102001995号