化工学报 ›› 2023, Vol. 74 ›› Issue (9): 3865-3878.DOI: 10.11949/0438-1157.20230501
张逸豪( ), 王振雷()
), 王振雷()
收稿日期:2023-05-23
修回日期:2023-08-30
出版日期:2023-09-25
发布日期:2023-11-20
通讯作者:
王振雷
作者简介:张逸豪(1999—),男,硕士研究生,sdzyh998710@163.com
基金资助:
Yihao ZHANG(), Zhenlei WANG()
Received:2023-05-23
Revised:2023-08-30
Online:2023-09-25
Published:2023-11-20
Contact:
Zhenlei WANG
摘要:
工业过程的众多变量之间往往存在着复杂的相关关系,传统的故障检测模型通常会忽略不同变量间相关性的差异,对不同相关关系的变量采用相同的特征提取方法,从而导致检测效果欠佳。针对以上问题,提出了一种基于最大信息系数的分组支持向量数据描述故障检测模型,首先计算变量间的最大信息系数矩阵,按照相关性的不同对变量进行分组,再通过最大信息系数为模型混合核函数中高斯核与多项式核的权重分配提供理论指导,从而分别为各组建立不同的支持向量数据描述检测模型,完成最大信息系数与支持向量数据描述的紧密结合,最终实现分布式故障检测。通过仿真对比,验证了该模型的可行性与有效性。
中图分类号:
张逸豪, 王振雷. 基于最大信息系数的分组支持向量数据描述故障检测[J]. 化工学报, 2023, 74(9): 3865-3878.
Yihao ZHANG, Zhenlei WANG. Fault detection using grouped support vector data description based on maximum information coefficient[J]. CIESC Journal, 2023, 74(9): 3865-3878.
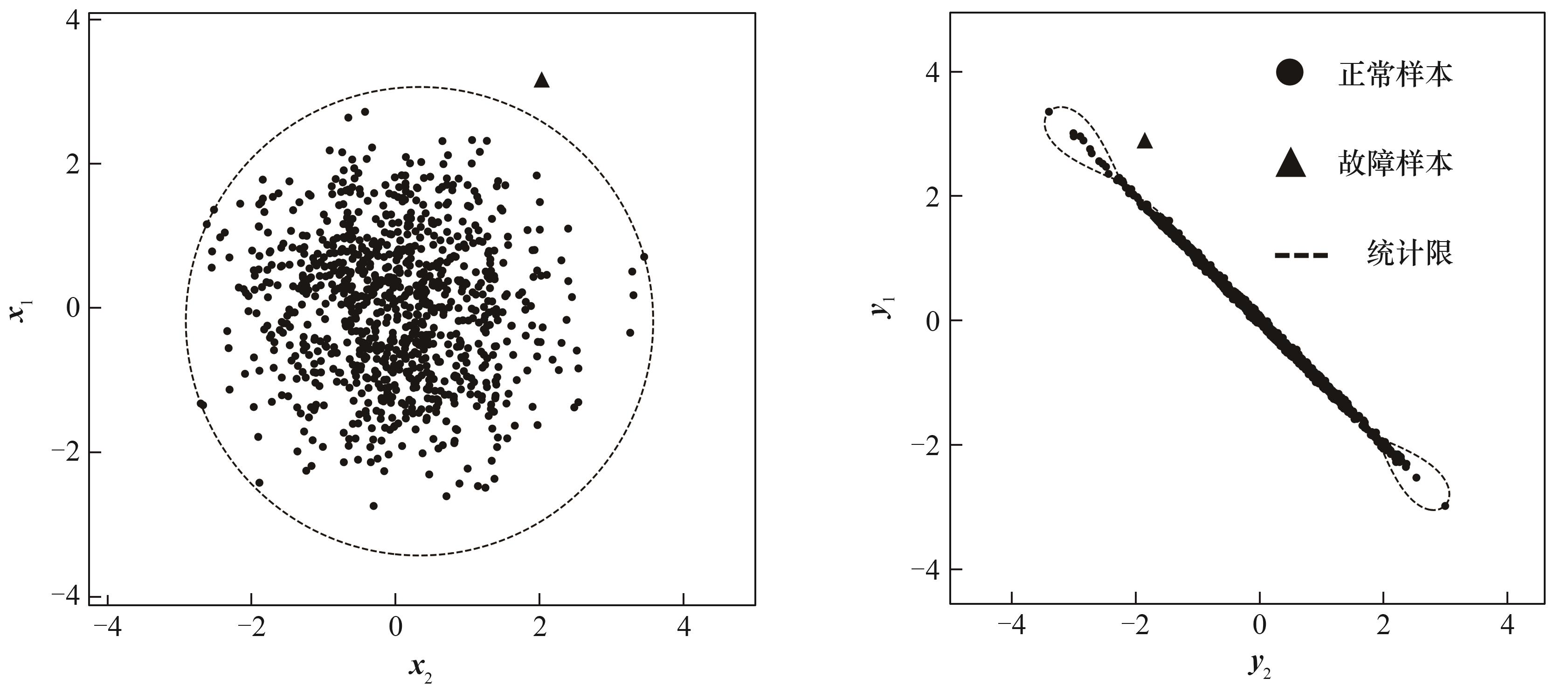
图1 SVDD超球体的二维投影
Fig.1 Projection of SVDD hypersphere in 2D space

图2 数据集 U960×4中四个变量间的相关关系
Fig.2 The correlation between the four variables in dataset U960×4

图3 全局核SVDD超球体的二维投影
Fig.3 Projection of global kernel SVDD hypersphere in 2D space
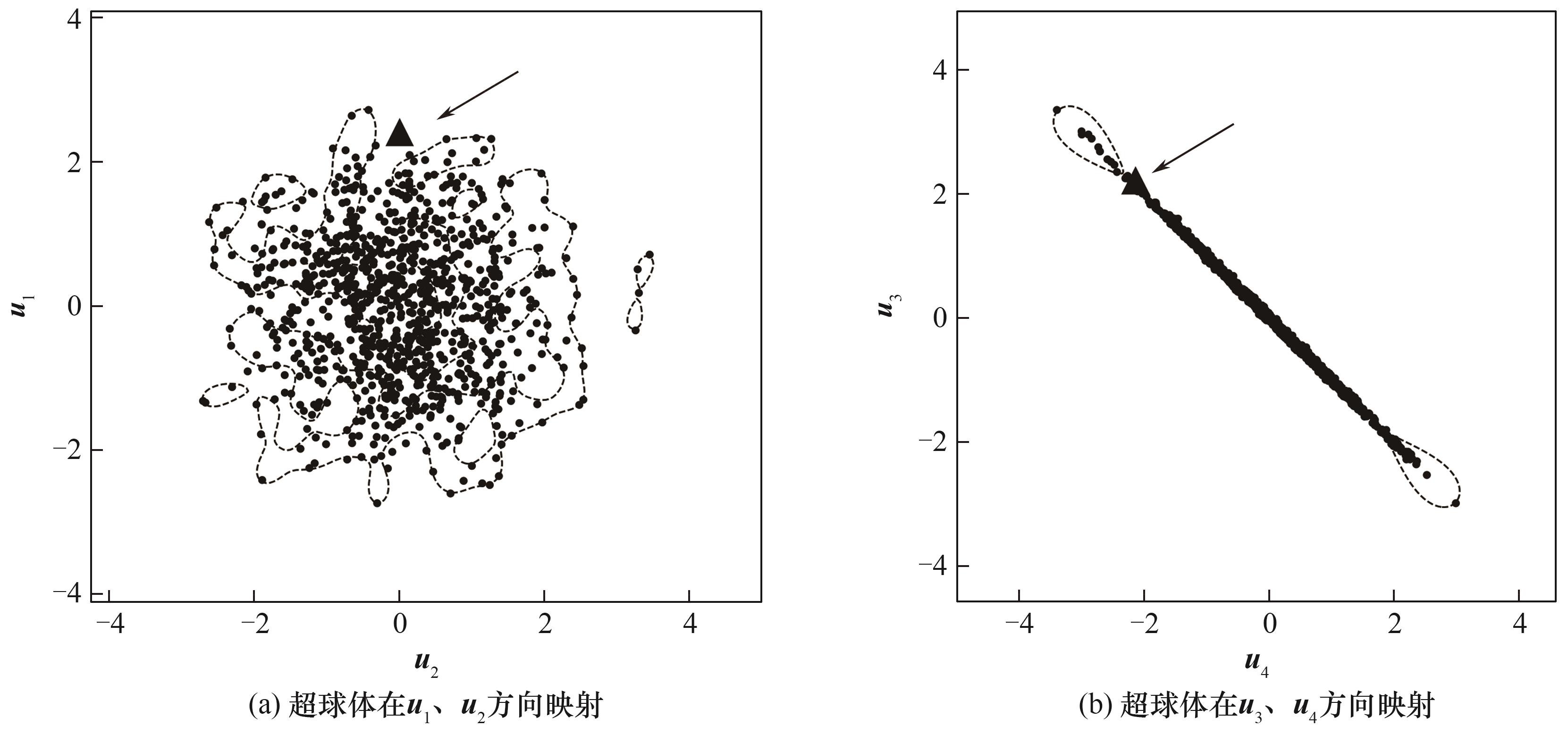
图4 局部核SVDD超球体的二维投影
Fig.4 Projection of local kernel SVDD hypersphere in 2D space
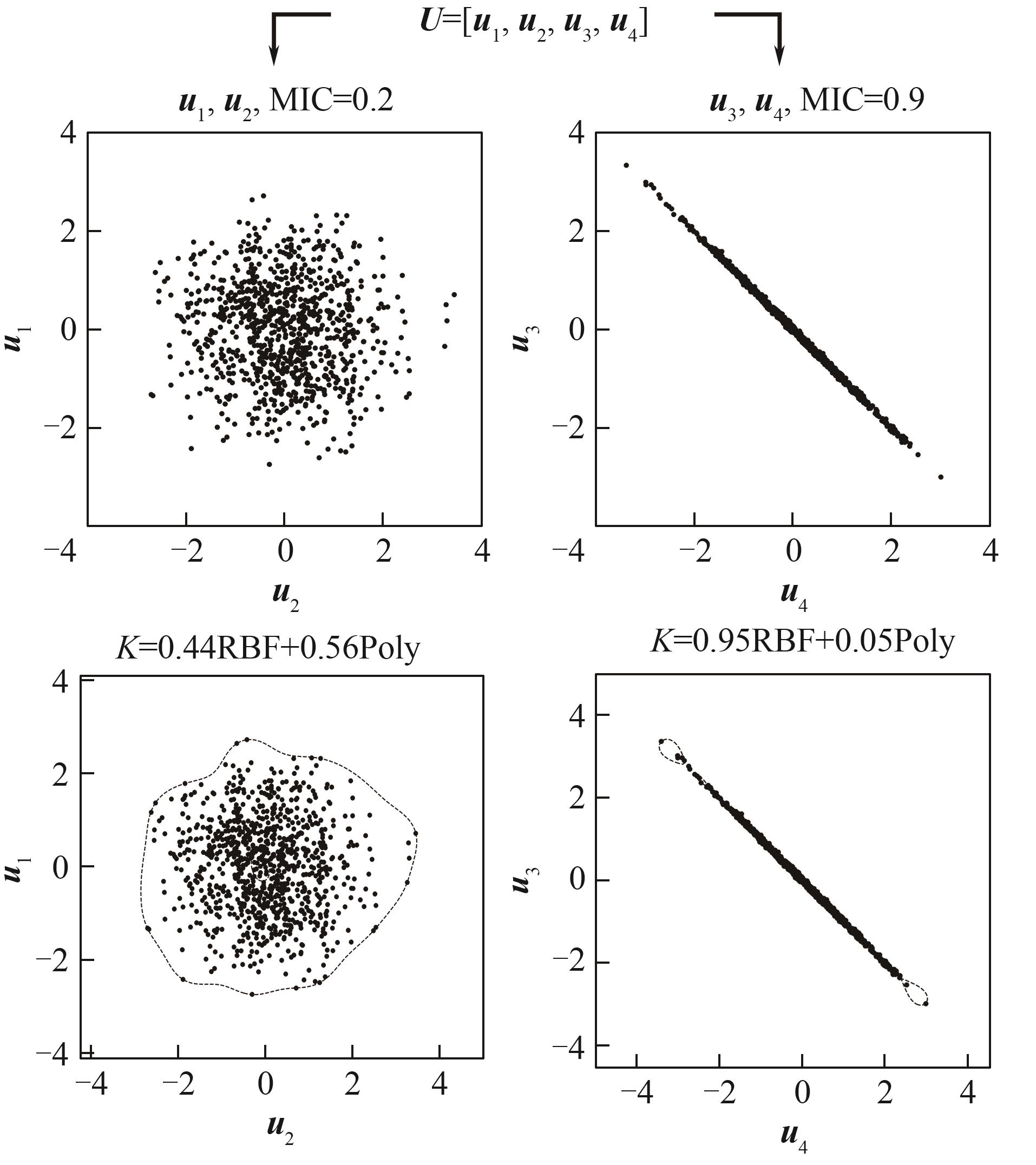
图5 基于MIC的分组建模示意图
Fig.5 Schematic diagram of MIC based grouping modeling
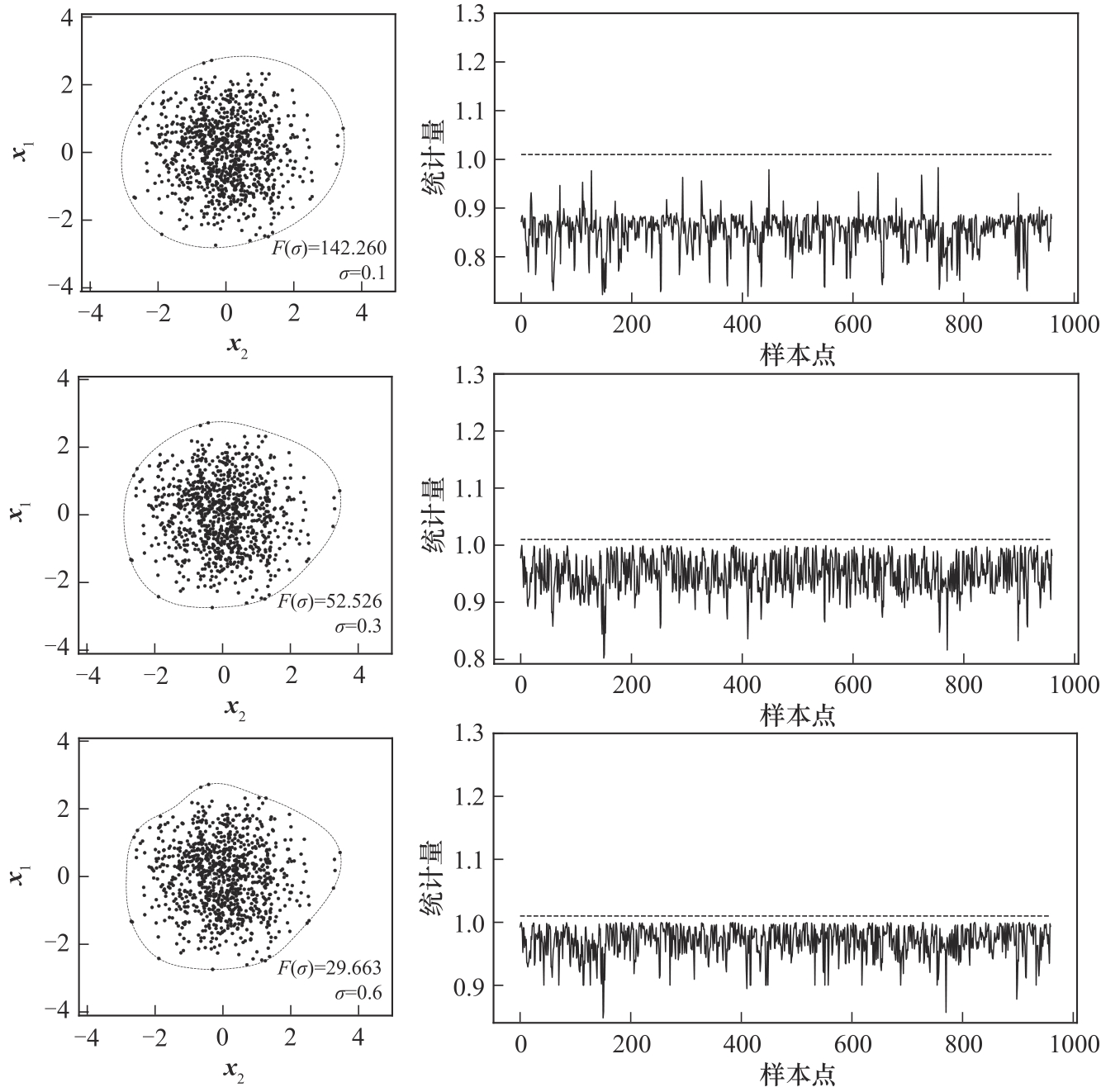
图6 σ的优化效果示意图
Fig.6 Schematic diagram of σ optimization effect
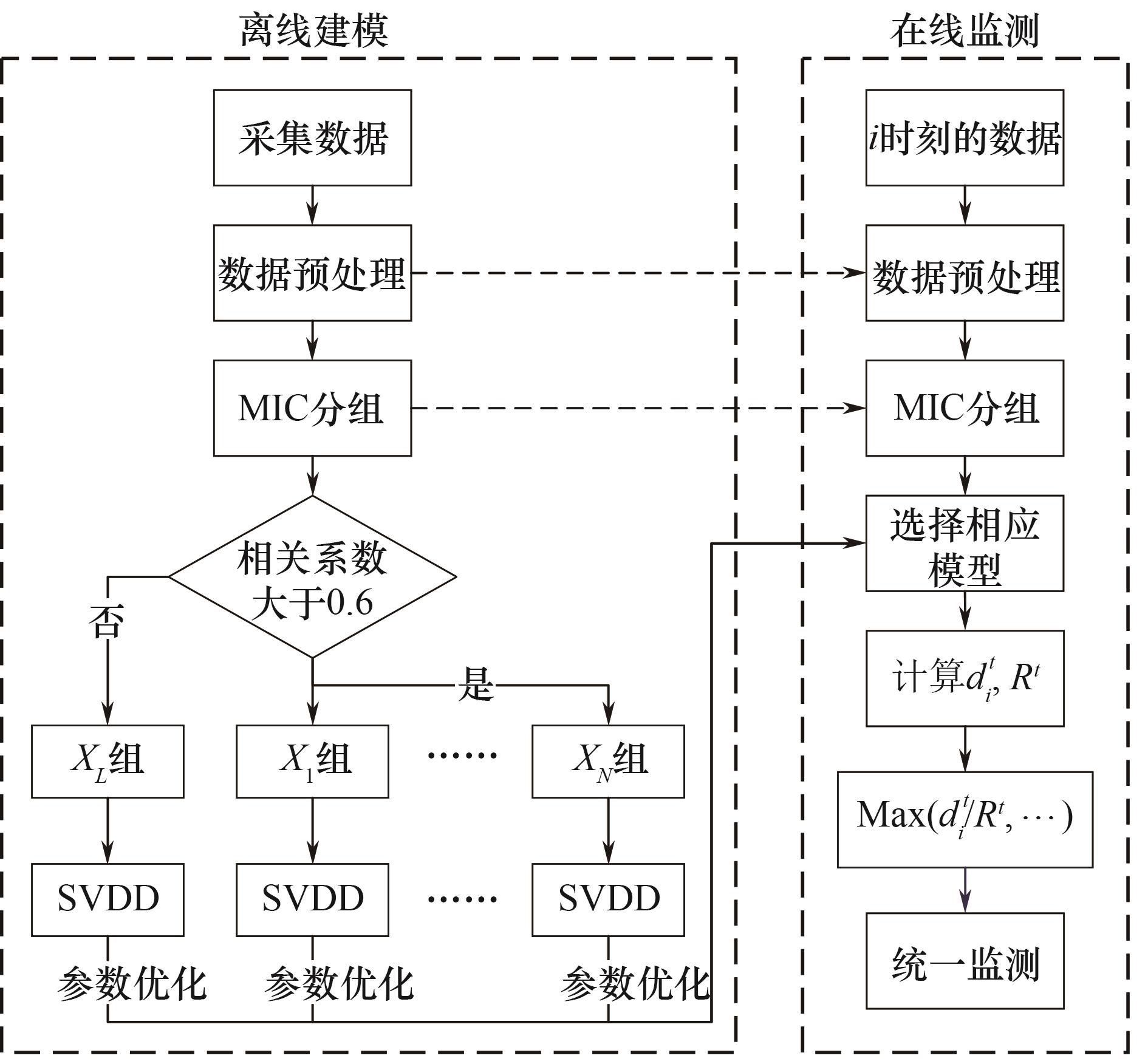
图7 MIC-SVDD建模与监测流程图
Fig.7 MIC-SVDD modeling and monitoring flowchart
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,2,5 | 0.895 | 5.012 |
| 2 | 3,4 | 0.179 | 2.258 |
表1 多变量过程分组情况及MIC-SVDD模型参数
Table 1 Multivariable process grouping and MIC-SVDD model parameter
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,2,5 | 0.895 | 5.012 |
| 2 | 3,4 | 0.179 | 2.258 |
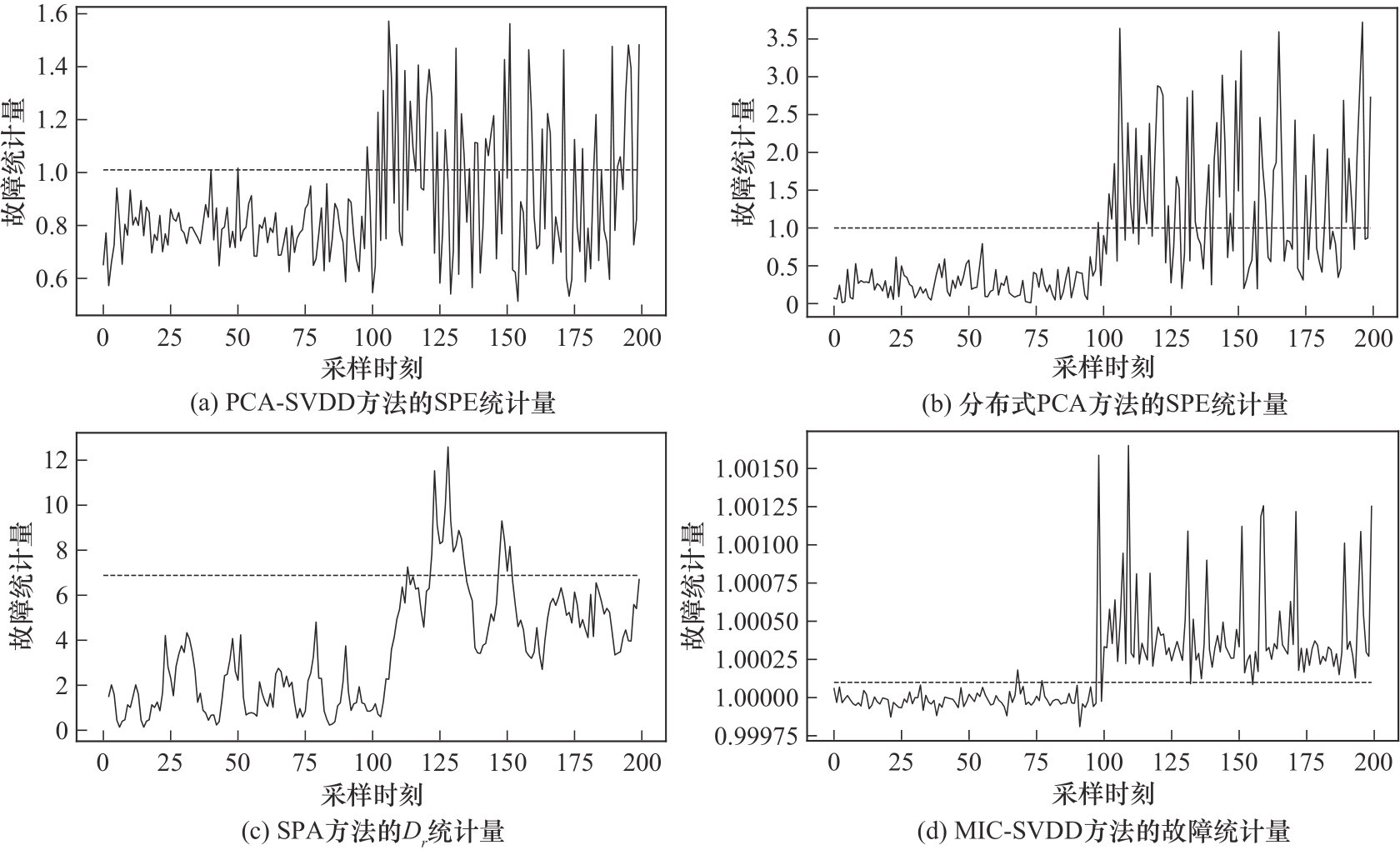
图8 四种方法对多变量过程的检测效果对比
Fig.8 Comparison of four methods for detecting multivariate processes
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,44 | 0.912 | 1.024 |
| 2 | 7,13,16 | 0.921 | 4.143 |
| 3 | 10,47 | 0.788 | 1.915 |
| 4 | 12,48 | 0.995 | 2.407 |
| 5 | 15,49 | 0.997 | 4.380 |
| 6 | 17,52 | 0.956 | 1.511 |
| 7 | 18,19,50 | 0.778 | 1.508 |
| 8 | 其余变量 | 0.066 | 3.427 |
表2 TE过程变量分组情况及MIC-SVDD模型参数
Table 2 TE process variable grouping and MIC-SVDD model parameter
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,44 | 0.912 | 1.024 |
| 2 | 7,13,16 | 0.921 | 4.143 |
| 3 | 10,47 | 0.788 | 1.915 |
| 4 | 12,48 | 0.995 | 2.407 |
| 5 | 15,49 | 0.997 | 4.380 |
| 6 | 17,52 | 0.956 | 1.511 |
| 7 | 18,19,50 | 0.778 | 1.508 |
| 8 | 其余变量 | 0.066 | 3.427 |
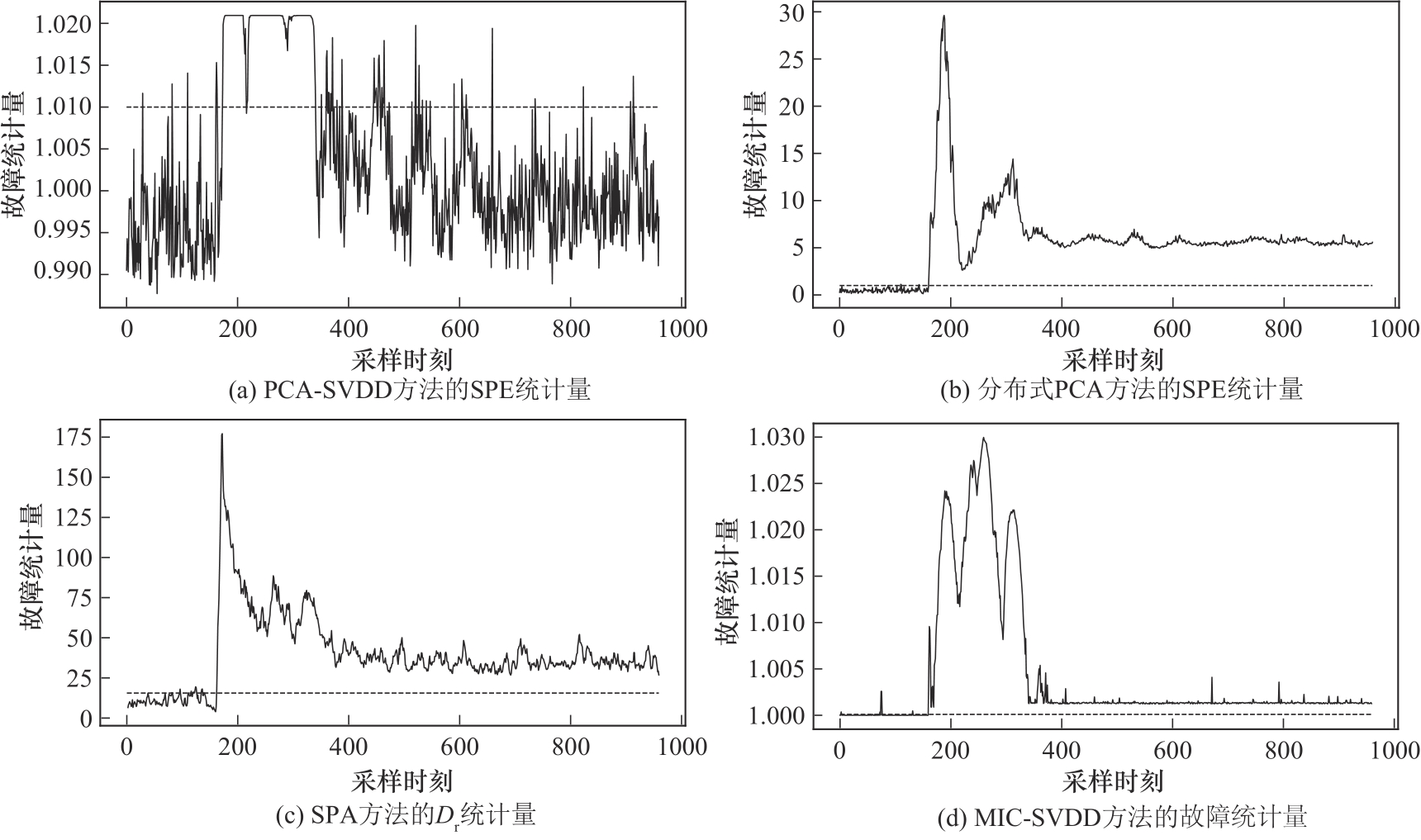
图9 四种方法对故障5的检测效果对比
Fig.9 Comparison of four methods for detecting fault 5
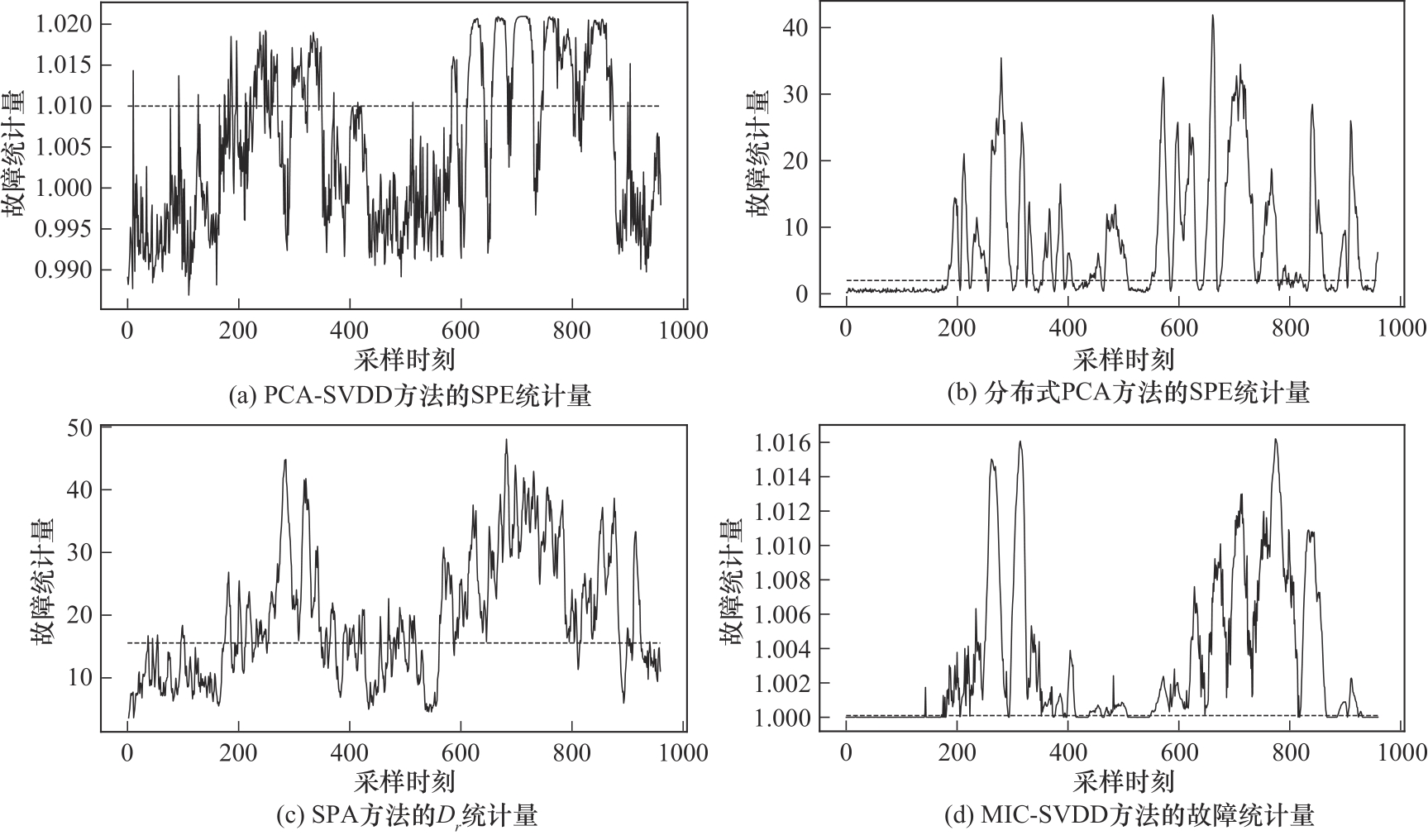
图10 四种方法对故障10的检测效果对比
Fig.10 Comparison of four methods for detecting fault 10
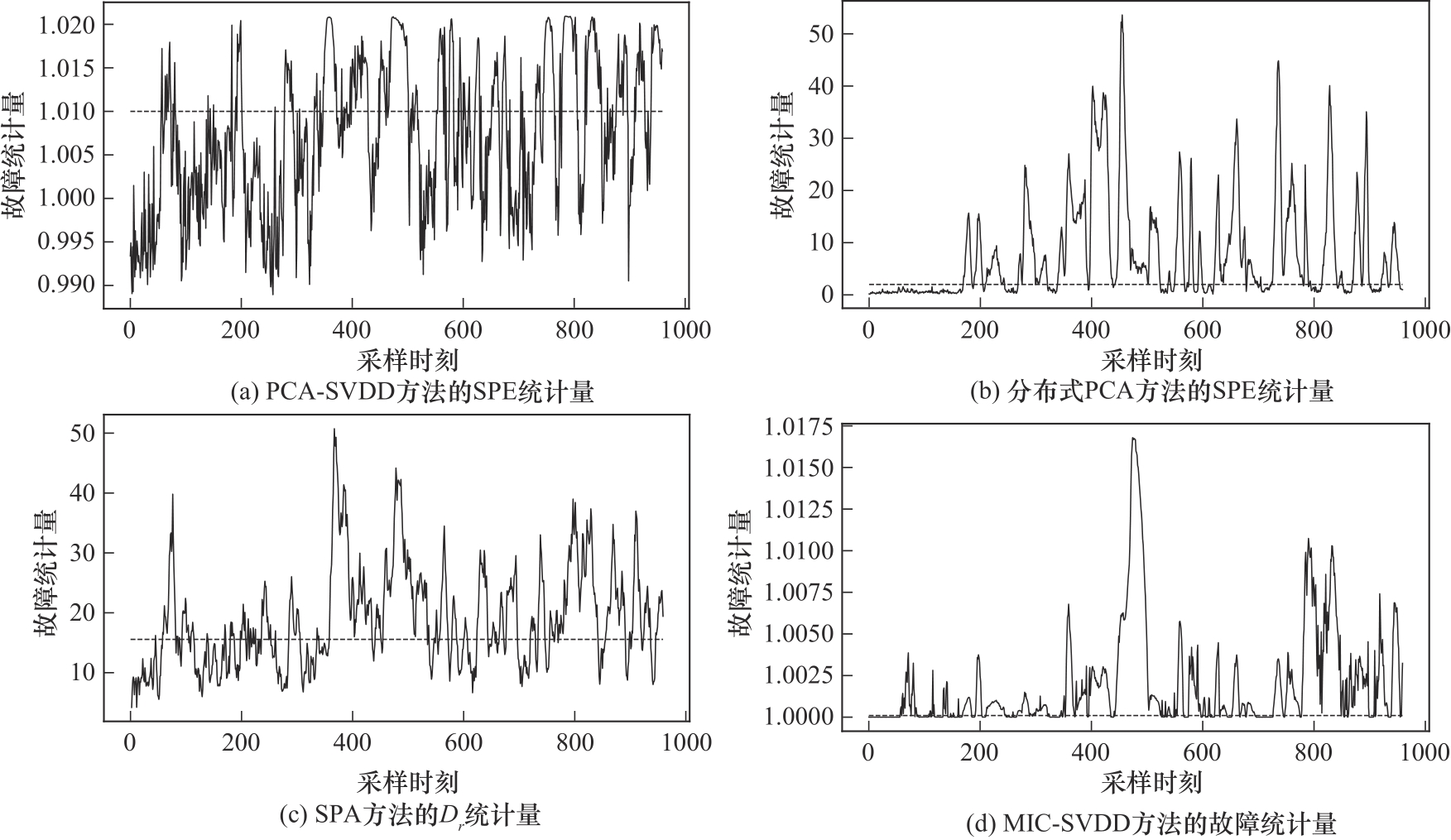
图11 四种方法对故障16的检测效果对比
Fig.11 Comparison of four methods for detecting fault 16
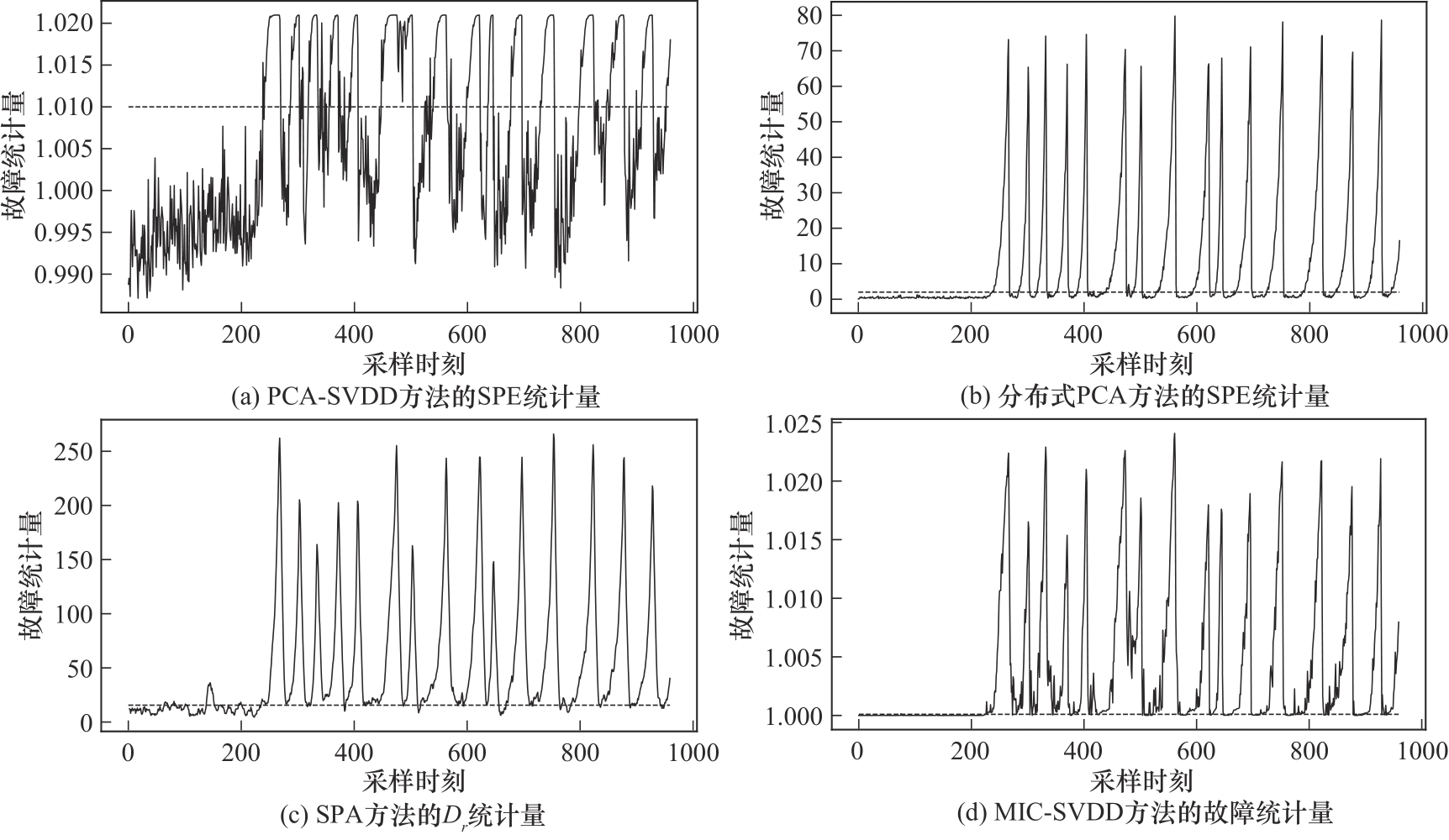
图12 四种方法对故障20的检测效果对比
Fig.12 Comparison of four methods for detecting fault 20
| 故障类型 | 故障检测率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 99.50 | 99.25 | 99.63 | 99.13 | 99.63 | 98.50 | 99.50 | 99.75 |
| 2 | 98.63 | 96.50 | 98.13 | 97.50 | 97.88 | 97.75 | 98.50 | 98.63 |
| 4 | 89.63 | 5.00 | 4.50 | 95.88 | 94.50 | 62.25 | 95.88 | 96.88 |
| 5 | 32.50 | 25.00 | 26.50 | 35.00 | 100.00 | 23.25 | 99.75 | 100.00 |
| 6 | 100.00 | 99.63 | 100.00 | 99.88 | 100.00 | 98.00 | 99.75 | 100.00 |
| 7 | 100.00 | 98.88 | 70.13 | 99.88 | 88.13 | 99.75 | 99.63 | 100.00 |
| 8 | 97.50 | 94.13 | 97.13 | 96.13 | 96.83 | 96.38 | 97.25 | 98.63 |
| 10 | 55.38 | 39.25 | 41.63 | 55.13 | 62.50 | 18.13 | 69.88 | 80.25 |
| 11 | 67.38 | 69.25 | 67.50 | 72.25 | 85.13 | 42.75 | 94.75 | 71.63 |
| 12 | 99.00 | 96.63 | 94.25 | 98.13 | 97.13 | 95.50 | 99.38 | 99.75 |
| 13 | 95.00 | 94.75 | 95.13 | 95.25 | 94.25 | 94.00 | 95.50 | 95.50 |
| 14 | 100.00 | 98.50 | 97.50 | 100.00 | 99.50 | 95.50 | 98.75 | 100.00 |
| 16 | 39.13 | 30.38 | 46.38 | 34.50 | 65.50 | 4.38 | 64.88 | 75.50 |
| 17 | 90.13 | 9.63 | 12.00 | 85.25 | 90.13 | 86.13 | 92.50 | 92.75 |
| 18 | 90.25 | 88.50 | 88.13 | 88.50 | 91.00 | 88.50 | 94.38 | 91.63 |
| 20 | 56.13 | 27.00 | 45.50 | 55.00 | 66.50 | 16.25 | 74.38 | 77.38 |
表3 SVDD、PCA-SVDD、分布式PCA、SPA、MIC-SVDD的故障检测率
Table 3 Fault detection rate of SVDD,PCA-SVDD,distributed PCA,SPA,MIC-SVDD
| 故障类型 | 故障检测率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 99.50 | 99.25 | 99.63 | 99.13 | 99.63 | 98.50 | 99.50 | 99.75 |
| 2 | 98.63 | 96.50 | 98.13 | 97.50 | 97.88 | 97.75 | 98.50 | 98.63 |
| 4 | 89.63 | 5.00 | 4.50 | 95.88 | 94.50 | 62.25 | 95.88 | 96.88 |
| 5 | 32.50 | 25.00 | 26.50 | 35.00 | 100.00 | 23.25 | 99.75 | 100.00 |
| 6 | 100.00 | 99.63 | 100.00 | 99.88 | 100.00 | 98.00 | 99.75 | 100.00 |
| 7 | 100.00 | 98.88 | 70.13 | 99.88 | 88.13 | 99.75 | 99.63 | 100.00 |
| 8 | 97.50 | 94.13 | 97.13 | 96.13 | 96.83 | 96.38 | 97.25 | 98.63 |
| 10 | 55.38 | 39.25 | 41.63 | 55.13 | 62.50 | 18.13 | 69.88 | 80.25 |
| 11 | 67.38 | 69.25 | 67.50 | 72.25 | 85.13 | 42.75 | 94.75 | 71.63 |
| 12 | 99.00 | 96.63 | 94.25 | 98.13 | 97.13 | 95.50 | 99.38 | 99.75 |
| 13 | 95.00 | 94.75 | 95.13 | 95.25 | 94.25 | 94.00 | 95.50 | 95.50 |
| 14 | 100.00 | 98.50 | 97.50 | 100.00 | 99.50 | 95.50 | 98.75 | 100.00 |
| 16 | 39.13 | 30.38 | 46.38 | 34.50 | 65.50 | 4.38 | 64.88 | 75.50 |
| 17 | 90.13 | 9.63 | 12.00 | 85.25 | 90.13 | 86.13 | 92.50 | 92.75 |
| 18 | 90.25 | 88.50 | 88.13 | 88.50 | 91.00 | 88.50 | 94.38 | 91.63 |
| 20 | 56.13 | 27.00 | 45.50 | 55.00 | 66.50 | 16.25 | 74.38 | 77.38 |
| 故障类型 | 正常工况误报率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 3.75 | 2.50 | 0 | 0.63 | 3.18 | 1.50 | 20.00 | 1.25 |
| 2 | 1.25 | 0.63 | 0.63 | 2.50 | 2.50 | 0 | 9.38 | 2.50 |
| 4 | 1.88 | 2.50 | 1.88 | 1.88 | 3.13 | 0 | 10.00 | 3.13 |
| 5 | 1.88 | 2.50 | 2.50 | 1.88 | 2.13 | 0.50 | 10.00 | 3.00 |
| 6 | 0.63 | 0 | 0 | 1.88 | 2.50 | 0 | 14.38 | 1.88 |
| 7 | 0.63 | 1.88 | 1.88 | 1.25 | 1.88 | 1.25 | 20.63 | 1.25 |
| 8 | 7.50 | 2.50 | 0.63 | 0.63 | 2.50 | 0.13 | 9.38 | 0.63 |
| 10 | 1.88 | 2.50 | 1.88 | 0 | 0.50 | 0 | 6.25 | 1.25 |
| 11 | 4.38 | 3.13 | 2.50 | 1.25 | 2.50 | 1.25 | 15.00 | 0.63 |
| 12 | 21.25 | 5.60 | 5.00 | 3.75 | 5.00 | 0 | 19.38 | 13.13 |
| 13 | 2.50 | 0 | 0 | 0.63 | 1.25 | 0 | 11.88 | 1.25 |
| 14 | 3.13 | 3.13 | 1.25 | 1.25 | 3.75 | 0 | 28.75 | 3.13 |
| 16 | 44.38 | 6.25 | 11.25 | 8.75 | 7.50 | 0 | 5.25 | 28.13 |
| 17 | 3.13 | 1.25 | 0.63 | 3.13 | 2.50 | 0 | 23.75 | 3.13 |
| 18 | 3.13 | 2.50 | 1.25 | 0.63 | 4.38 | 0.50 | 18.75 | 1.25 |
| 20 | 1.25 | 0 | 0 | 0.63 | 3.75 | 0 | 18.13 | 0.63 |
表4 SVDD、PCA-SVDD、分布式PCA、SPA、MIC-SVDD的正常工况误报率
Table 4 False alarm rate of SVDD,PCA-SVDD,distributed PCA,SPA,MIC-SVDD
| 故障类型 | 正常工况误报率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 3.75 | 2.50 | 0 | 0.63 | 3.18 | 1.50 | 20.00 | 1.25 |
| 2 | 1.25 | 0.63 | 0.63 | 2.50 | 2.50 | 0 | 9.38 | 2.50 |
| 4 | 1.88 | 2.50 | 1.88 | 1.88 | 3.13 | 0 | 10.00 | 3.13 |
| 5 | 1.88 | 2.50 | 2.50 | 1.88 | 2.13 | 0.50 | 10.00 | 3.00 |
| 6 | 0.63 | 0 | 0 | 1.88 | 2.50 | 0 | 14.38 | 1.88 |
| 7 | 0.63 | 1.88 | 1.88 | 1.25 | 1.88 | 1.25 | 20.63 | 1.25 |
| 8 | 7.50 | 2.50 | 0.63 | 0.63 | 2.50 | 0.13 | 9.38 | 0.63 |
| 10 | 1.88 | 2.50 | 1.88 | 0 | 0.50 | 0 | 6.25 | 1.25 |
| 11 | 4.38 | 3.13 | 2.50 | 1.25 | 2.50 | 1.25 | 15.00 | 0.63 |
| 12 | 21.25 | 5.60 | 5.00 | 3.75 | 5.00 | 0 | 19.38 | 13.13 |
| 13 | 2.50 | 0 | 0 | 0.63 | 1.25 | 0 | 11.88 | 1.25 |
| 14 | 3.13 | 3.13 | 1.25 | 1.25 | 3.75 | 0 | 28.75 | 3.13 |
| 16 | 44.38 | 6.25 | 11.25 | 8.75 | 7.50 | 0 | 5.25 | 28.13 |
| 17 | 3.13 | 1.25 | 0.63 | 3.13 | 2.50 | 0 | 23.75 | 3.13 |
| 18 | 3.13 | 2.50 | 1.25 | 0.63 | 4.38 | 0.50 | 18.75 | 1.25 |
| 20 | 1.25 | 0 | 0 | 0.63 | 3.75 | 0 | 18.13 | 0.63 |

图13 管式裂解炉结构简图
Fig.13 Structural diagram of tubular cracking furnace
| 编号 | 变量 | 单位 | 编号 | 变量 | 单位 | 编号 | 变量 | 单位 |
|---|---|---|---|---|---|---|---|---|
| 1 | 裂解原料密度 | kg/m3 | 7 | 原料进料流量 | t/h | 13 | 高压蒸汽温度 | ℃ |
| 2 | 成分A浓度 | %(摩尔) | 8 | 稀释蒸汽流量 | t/h | 14 | 炉管出口温度 | ℃ |
| 3 | 成分B浓度 | %(摩尔) | 9 | 排烟温度1 | ℃ | 15 | 侧壁燃料流量 | m3/h |
| 4 | 成分C浓度 | %(摩尔) | 10 | 排烟温度2 | ℃ | 16 | 底部燃料流量 | m3/h |
| 5 | 成分D浓度 | %(摩尔) | 11 | 排烟氧含量 | %(摩尔) | |||
| 6 | 成分E浓度 | %(摩尔) | 12 | 高压蒸汽流量 | kg/h |
表5 裂解炉工艺参数
Table 5 Process parameter of cracking furnace
| 编号 | 变量 | 单位 | 编号 | 变量 | 单位 | 编号 | 变量 | 单位 |
|---|---|---|---|---|---|---|---|---|
| 1 | 裂解原料密度 | kg/m3 | 7 | 原料进料流量 | t/h | 13 | 高压蒸汽温度 | ℃ |
| 2 | 成分A浓度 | %(摩尔) | 8 | 稀释蒸汽流量 | t/h | 14 | 炉管出口温度 | ℃ |
| 3 | 成分B浓度 | %(摩尔) | 9 | 排烟温度1 | ℃ | 15 | 侧壁燃料流量 | m3/h |
| 4 | 成分C浓度 | %(摩尔) | 10 | 排烟温度2 | ℃ | 16 | 底部燃料流量 | m3/h |
| 5 | 成分D浓度 | %(摩尔) | 11 | 排烟氧含量 | %(摩尔) | |||
| 6 | 成分E浓度 | %(摩尔) | 12 | 高压蒸汽流量 | kg/h |
| 编号 | 故障类型 |
|---|---|
| 1 | 裂解气大阀逐渐关闭 |
| 2 | 裂解炉对流段积灰 |
| 3 | 裂解炉炉管渗漏 |
表6 裂解炉故障类型
Table 6 Cracking furnace fault type
| 编号 | 故障类型 |
|---|---|
| 1 | 裂解气大阀逐渐关闭 |
| 2 | 裂解炉对流段积灰 |
| 3 | 裂解炉炉管渗漏 |
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,2,3,4,9,13,14,16 | 0.874 | 1.284 |
| 2 | 5,6,7,8,10,11,12,15 | 0.184 | 3.868 |
表7 乙烯裂解炉变量分组情况及MIC-SVDD模型参数
Table 7 Variable grouping of ethylene cracking furnace and MIC-SVDD model parameter table
| 变量组编号 | 所含变量编号 | 高斯核权重 | 高斯核参数 |
|---|---|---|---|
| 1 | 1,2,3,4,9,13,14,16 | 0.874 | 1.284 |
| 2 | 5,6,7,8,10,11,12,15 | 0.184 | 3.868 |
故障 类型 | 故障检测率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 78.00 | 37.00 | 40.00 | 73.00 | 81.00 | 75.00 | 82.00 | 90.00 |
| 2 | 80.00 | 50.00 | 56.00 | 28.00 | 50.00 | 58.00 | 60.00 | 88.00 |
| 3 | 30.00 | 8.00 | 12.00 | 23.00 | 35.00 | 28.00 | 37.00 | 46.00 |
表8 SVDD、PCA-SVDD、分布式PCA、SPA、MIC-SVDD的故障检测率
Table 8 Fault detection rate of SVDD,PCA-SVDD,distributed PCA,SPA,MIC-SVDD
故障 类型 | 故障检测率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 1 | 78.00 | 37.00 | 40.00 | 73.00 | 81.00 | 75.00 | 82.00 | 90.00 |
| 2 | 80.00 | 50.00 | 56.00 | 28.00 | 50.00 | 58.00 | 60.00 | 88.00 |
| 3 | 30.00 | 8.00 | 12.00 | 23.00 | 35.00 | 28.00 | 37.00 | 46.00 |
| 故障类型 | 正常工况误报率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 正常 | 7.00 | 0.00 | 2.00 | 0.50 | 3.00 | 3.00 | 6.00 | 6.00 |
| 1 | 1.00 | 0.00 | 1.00 | 1.00 | 2.00 | 2.00 | 5.00 | 4.00 |
| 2 | 3.00 | 2.00 | 3.00 | 5.00 | 4.00 | 1.00 | 4.00 | 3.00 |
| 3 | 7.00 | 0.00 | 0.00 | 2.00 | 4.00 | 2.00 | 2.00 | 3.00 |
表9 SVDD、PCA-SVDD、分布式PCA、SPA、MIC-SVDD的正常工况误报率
Table 9 False alarm rate of SVDD,PCA-SVDD,distributed PCA,SPA,MIC-SVDD
| 故障类型 | 正常工况误报率/% | |||||||
|---|---|---|---|---|---|---|---|---|
| SVDD | PCA-SVDD | 分布式PCA | SPA | MIC-SVDD | ||||
| T2 | SPE | T2 | SPE | Dp | Dr | |||
| 正常 | 7.00 | 0.00 | 2.00 | 0.50 | 3.00 | 3.00 | 6.00 | 6.00 |
| 1 | 1.00 | 0.00 | 1.00 | 1.00 | 2.00 | 2.00 | 5.00 | 4.00 |
| 2 | 3.00 | 2.00 | 3.00 | 5.00 | 4.00 | 1.00 | 4.00 | 3.00 |
| 3 | 7.00 | 0.00 | 0.00 | 2.00 | 4.00 | 2.00 | 2.00 | 3.00 |
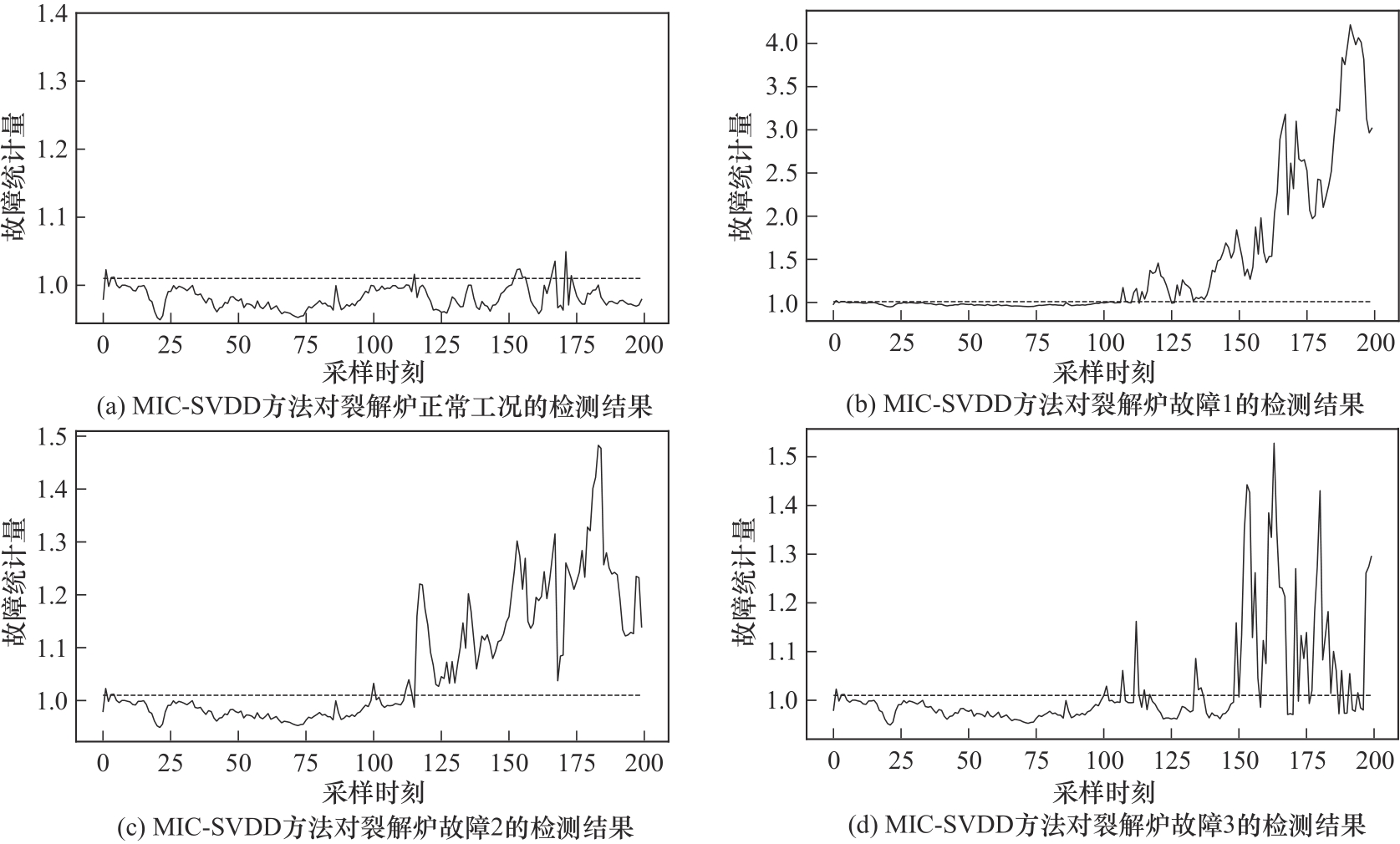
图14 MIC-SVDD方法对裂解炉故障的检测效果
Fig.14 The detection effect of MIC-SVDD method on cracking furnace faults
| 1 | Chiang L H, Braatz R D. Process monitoring using causal map and multivariate statistics: fault detection and identification[J]. Chemometrics and Intelligent Laboratory Systems, 2003, 65(2): 159-178. |
| 2 | 董顺, 李益国, 孙栓柱, 等. 基于状态空间主成分分析网络的故障检测方法[J]. 化工学报, 2018, 69(8): 3528-3536. |
| Dong S, Li Y G, Sun S Z, et al. Fault detection method based on state space-PCANet[J]. CIESC Journal, 2018, 69(8): 3528-3536. | |
| 3 | Thornhill N F, Shoukat Choudhury M A A, Shah S L. The impact of compression on data-driven process analyses[J]. Journal of Process Control, 2004, 14(4): 389-398. |
| 4 | Manikandan S, Duraivelu K. Fault diagnosis of various rotating equipment using machine learning approaches—a review[J]. Proceedings of the Institution of Mechanical Engineers, Part E: Journal of Process Mechanical Engineering, 2021, 235(2): 629-642. |
| 5 | Jin X H, Fan J C, Chow T W S. Fault detection for rolling-element bearings using multivariate statistical process control methods[J]. IEEE Transactions on Instrumentation and Measurement, 2019, 68(9): 3128-3136. |
| 6 | Morris A J, Martin E B. Process performance monitoring and fault detection through multivariate statistical process control[J]. IFAC Proceedings Volumes, 1997, 30(18): 1-14. |
| 7 | 徐静, 王振雷, 王昕. 基于非线性动态全局局部保留投影算法的化工过程故障检测[J]. 化工学报, 2020, 71(12): 5655-5663. |
| Xu J, Wang Z L, Wang X. Fault detection for chemical process based on nonlinear dynamic global-local preserving projections[J]. CIESC Journal, 2020, 71(12): 5655-5663. | |
| 8 | Asghar F, Talha M, Kim S Y, et al. Hotelling T 2 index based PCA method for fault detection in transient state processes[J]. Journal of Institute of Control, Robotics and Systems, 2016, 22(4): 276-280. |
| 9 | Kano M, Tanaka S, Maruta H, et al. Statistical process monitoring with external analysis and independent component analysis[J]. Transactions of the Society of Instrument and Control Engineers, 2002, 38(11): 958-965. |
| 10 | 王雅琳, 潘雨晴, 刘晨亮. 基于GSA-LSTM动态结构特征提取的间歇过程监测方法[J]. 化工学报, 2022, 73(9): 3994-4002. |
| Wang Y L, Pan Y Q, Liu C L. Intermittent process monitoring based on GSA-LSTM dynamic structure feature extraction[J]. CIESC Journal, 2022, 73(9): 3994-4002. | |
| 11 | Li S, Wang H Q, Song L Y, et al. An adaptive data fusion strategy for fault diagnosis based on the convolutional neural network[J]. Measurement, 2020, 165: 108122. |
| 12 | Rani J, Tripura T, Kodamana H, et al. Fault detection and isolation using probabilistic wavelet neural operator auto-encoder with application to dynamic processes[J]. Process Safety and Environmental Protection, 2023, 173: 215-228. |
| 13 | Tan L Y, Huang T T, Liu J, et al. Deep adversarial learning system for fault diagnosis in fused deposition modeling with imbalanced data[J]. Computers & Industrial Engineering, 2023, 176: 108887. |
| 14 | Shi P M, Gao H, Yu Y, et al. Intelligent fault diagnosis of rolling mills based on dual attention-guided deep learning method under imbalanced data conditions[J]. Measurement, 2022, 204: 111993. |
| 15 | 李冠男, 胡云鹏, 陈焕新, 等. 基于SVDD的冷水机组传感器故障检测及效率分析[J]. 化工学报, 2015, 66(5): 1815-1820. |
| Li G N, Hu Y P, Chen H X, et al. SVDD-based chiller sensor fault detection method and its detection efficiency[J]. CIESC Journal, 2015, 66(5): 1815-1820. | |
| 16 | Deng X G, Zhang Z. Nonlinear chemical process fault diagnosis using ensemble deep support vector data description[J]. Sensors, 2020, 20(16): 4599. |
| 17 | Gu X, Yang S, Xu X, et al. Fault detecting using support vector data description with genetic algorithm[C]//Proceedings of the International Conference on Mechanical Engineering and Mechanics. Science Press USA Inc., 2005: 650-652. |
| 18 | Zhuang J F, Luo J, Peng Y Q, et al. On-line fault detection method based on modified SVDD for industrial process system[C]//2008 3rd International Conference on Intelligent System and Knowledge Engineering. IEEE, 2008: 754-760. |
| 19 | Ge Z Q, Gao F R, Song Z H. Batch process monitoring based on support vector data description method[J]. Journal of Process Control, 2011, 21(6): 949-959. |
| 20 | Ren D F, Hui M, Hu N, et al. A weighted sparse neighbor representation based on Gaussian kernel function to face recognition[J]. Optik, 2018, 167: 7-14. |
| 21 | Yi Y S, Zhao H T, Hu Z W, et al. A local-global transformer for distributed monitoring of multi-unit nonlinear processes[J]. Journal of Process Control, 2023, 122: 13-26. |
| 22 | 曹力, 潘巧波, 王明宇, 等. 基于混合核函数支持向量机的风电机组发电机温度预警方法[J]. 华电技术, 2020, 42(5): 43-49. |
| Cao L, Pan Q B, Wang M Y, et al. Early warning method for wind turbine generator temperature based on HK-SVM[J]. Huadian Technology, 2020, 42(5): 43-49. | |
| 23 | Wang B J, Zhang X L, Xing S, et al. Sparse representation theory for support vector machine kernel function selection and its application in high-speed bearing fault diagnosis[J]. ISA Transactions, 2021, 118: 207-218. |
| 24 | 江伟, 王振雷, 王昕. 基于混合分块DMICA-PCA的全流程过程监控方法[J]. 化工学报, 2017, 68(2): 759-766. |
| Jiang W, Wang Z L, Wang X. Plant-wide process monitoring based on mixed multiblock DMICA-PCA[J]. CIESC Journal, 2017, 68(2): 759-766. | |
| 25 | 童楚东, 史旭华. 基于互信息的PCA方法及其在过程监测中的应用[J]. 化工学报, 2015, 66(10): 4101-4106. |
| Tong C D, Shi X H. Mutual information based PCA algorithm with application in process monitoring[J]. CIESC Journal, 2015, 66(10): 4101-4106. | |
| 26 | 任佳, 孙思宇, 鲍克. 基于最大信息系数和深度残差图卷积的工业过程故障诊断方法[J]. 高校化学工程学报, 2023, 37(1): 111-119. |
| Ren J, Sun S Y, Bao K. Fault diagnosis method in industrial processes based on maximal information coefficient and depth residual graph convolution[J]. Journal of Chemical Engineering of Chinese Universities, 2023, 37(1): 111-119. | |
| 27 | 赵帅, 宋冰, 侍洪波. 基于加权互信息主元分析算法的质量相关故障检测[J]. 化工学报, 2018, 69(3): 962-973. |
| Zhao S, Song B, Shi H B. Quality-related fault detection based on weighted mutual information principal component analysis[J]. CIESC Journal, 2018, 69(3): 962-973. | |
| 28 | Huang J, Yan X F. Related and independent variable fault detection based on KPCA and SVDD[J]. Journal of Process Control, 2016, 39: 88-99. |
| 29 | Tax D M J, Duin R P W. Support vector data description[J]. Machine Learning, 2004, 54(1): 45-66. |
| 30 | Wang J, He Q P. Multivariate statistical process monitoring based on statistics pattern analysis[J]. Industrial & Engineering Chemistry Research, 2010, 49(17): 7858-7869. |
| 31 | Downs J J, Vogel E F. A plant-wide industrial process control problem[J]. Computers & Chemical Engineering, 1993, 17(3): 245-255. |
| [1] | 邵远哲, 赵忠盖, 刘飞. 基于共同趋势模型的非平稳过程质量相关故障检测方法[J]. 化工学报, 2023, 74(6): 2522-2537. |
| [2] | 宋冰, 郑城风, 侍洪波, 陶阳, 谭帅. 基于VAE-OCCA的质量相关故障检测方法研究[J]. 化工学报, 2023, 74(4): 1630-1638. |
| [3] | 雍加望, 赵倩倩, 冯能莲. 基于非线性动态模型的质子交换膜燃料电池故障诊断[J]. 化工学报, 2022, 73(9): 3983-3993. |
| [4] | 杨明辉, 刘晓月, 邓晓刚, 廖明燕, 侯春望. 基于加权概率CVDA的动态化工系统微小故障检测[J]. 化工学报, 2022, 73(9): 3963-3972. |
| [5] | 郭金玉, 王哲, 李元. 基于核熵独立成分分析的故障检测方法[J]. 化工学报, 2022, 73(8): 3647-3658. |
| [6] | 王琨, 侍洪波, 谭帅, 宋冰, 陶阳. 局部时差约束邻域保持嵌入算法在故障检测中的应用[J]. 化工学报, 2022, 73(7): 3109-3119. |
| [7] | 郭金玉, 李文涛, 李元. 在线压缩KECA的自适应算法在故障检测中的应用[J]. 化工学报, 2021, 72(8): 4227-4238. |
| [8] | 顾俊发, 许明阳, 马方圆, 林治宇, 纪成, 王璟德, 孙巍. 基于MIC的支持向量回归及其在化工过程中的应用[J]. 化工学报, 2021, 72(3): 1480-1486. |
| [9] | 李元, 杨东昇, 赵丽颖, 张成. 层次变分高斯混合模型与主多项式分析的故障检测策略[J]. 化工学报, 2021, 72(3): 1616-1626. |
| [10] | 王晓慧, 王延江, 邓晓刚, 张政. 基于加权深度支持向量数据描述的工业过程故障检测[J]. 化工学报, 2021, 72(11): 5707-5716. |
| [11] | 邓明月, 刘建昌, 许鹏, 谭树彬, 商亮亮. 基于KECA的非线性工业过程故障检测与诊断新方法[J]. 化工学报, 2020, 71(5): 2151-2163. |
| [12] | 韩宇, 李俊芳, 高强, 田宇, 禹国刚. 基于故障判别增强KECA算法的故障检测[J]. 化工学报, 2020, 71(3): 1254-1263. |
| [13] | 徐静,王振雷,王昕. 基于非线性动态全局局部保留投影算法的化工过程故障检测[J]. 化工学报, 2020, 71(12): 5655-5663. |
| [14] | 孙中建,杨博,齐楚,李宏光. 面向工业混杂系统故障检测的扩展数据逻辑分析方法[J]. 化工学报, 2020, 71(11): 5237-5245. |
| [15] | 于蕾, 邓晓刚, 曹玉苹, 路凯琪. 基于变量分组DTW-MCVA的不等长间歇过程故障检测方法[J]. 化工学报, 2019, 70(9): 3441-3448. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备 11010102001995号
京公网安备 11010102001995号

