CIESC Journal ›› 2020, Vol. 71 ›› Issue (8): 3661-3670.DOI: 10.11949/0438-1157.20191115
• Process system engineering • Previous Articles Next Articles
Linzi YIN1( ),Yuyin GUAN1,Zhaohui JIANG2,Xuemei XU1
),Yuyin GUAN1,Zhaohui JIANG2,Xuemei XU1
Received:2019-10-07
Revised:2020-05-16
Online:2020-08-05
Published:2020-08-05
Contact:
Linzi YIN
尹林子1(),关羽吟1,蒋朝辉2,许雪梅1
通讯作者:
尹林子
作者简介:尹林子(1980—),男,博士,副教授,基金资助:CLC Number:
Linzi YIN, Yuyin GUAN, Zhaohui JIANG, Xuemei XU. Optimal method of selecting silicon content data in blast furnace hot metal based on k-means++[J]. CIESC Journal, 2020, 71(8): 3661-3670.
尹林子, 关羽吟, 蒋朝辉, 许雪梅. 基于k-means++的高炉铁水硅含量数据优选方法[J]. 化工学报, 2020, 71(8): 3661-3670.
Add to citation manager EndNote|Ris|BibTeX
| 样本周期内的硅含量检测数目 | 样本数 | 占比/% |
|---|---|---|
| 0 | 79 | 10.63 |
| 1 | 184 | 24.76 |
| 2 | 243 | 32.7 |
| 3 | 166 | 22.34 |
| 4 | 54 | 7.27 |
| 5 | 15 | 2.02 |
| 7 | 1 | 0.13 |
| 9 | 1 | 0.13 |
Table 1 The proportion of different silicon contents during the sample period
| 样本周期内的硅含量检测数目 | 样本数 | 占比/% |
|---|---|---|
| 0 | 79 | 10.63 |
| 1 | 184 | 24.76 |
| 2 | 243 | 32.7 |
| 3 | 166 | 22.34 |
| 4 | 54 | 7.27 |
| 5 | 15 | 2.02 |
| 7 | 1 | 0.13 |
| 9 | 1 | 0.13 |
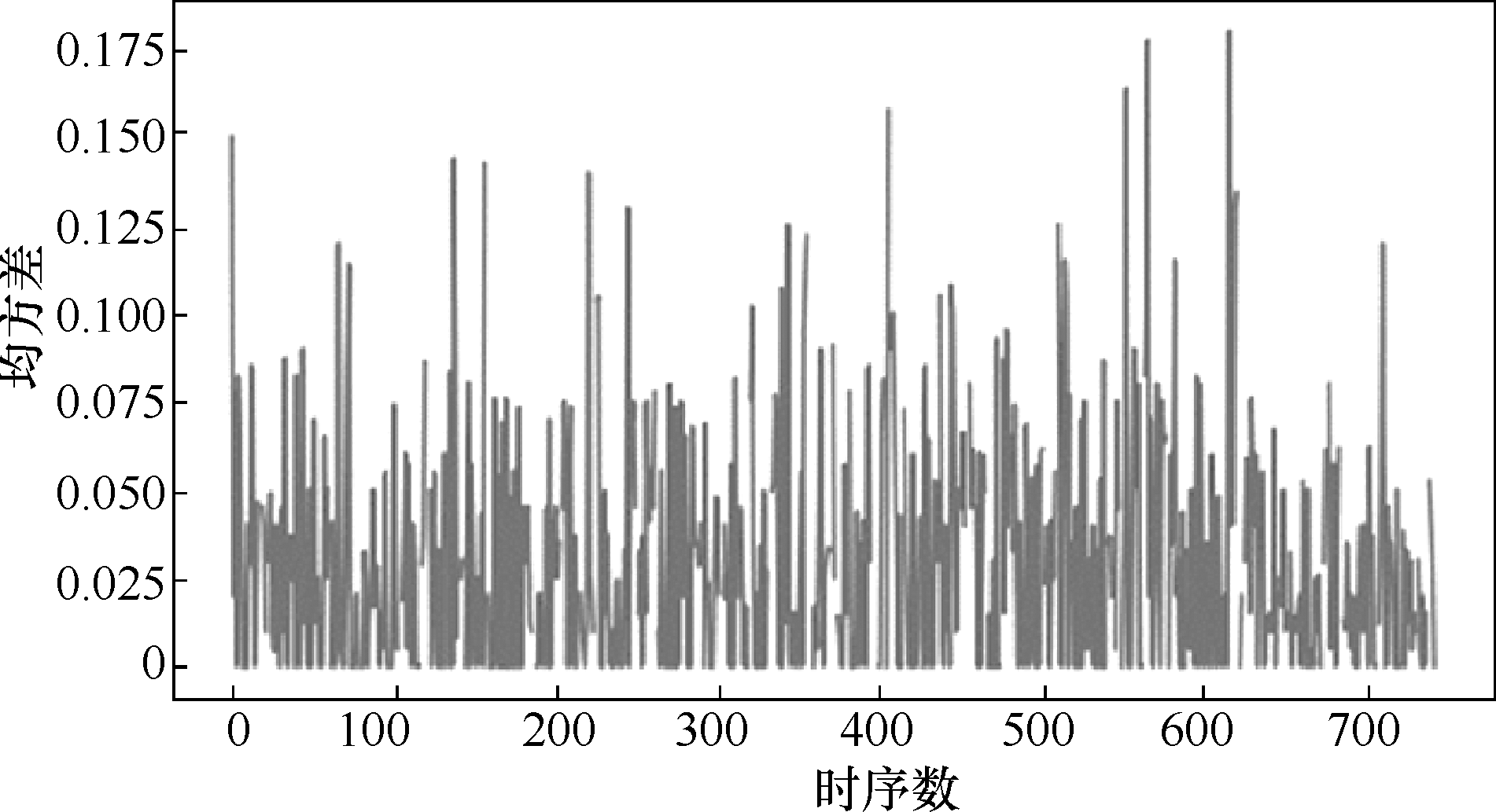
Fig.1 MSE of silicon content for each sample period
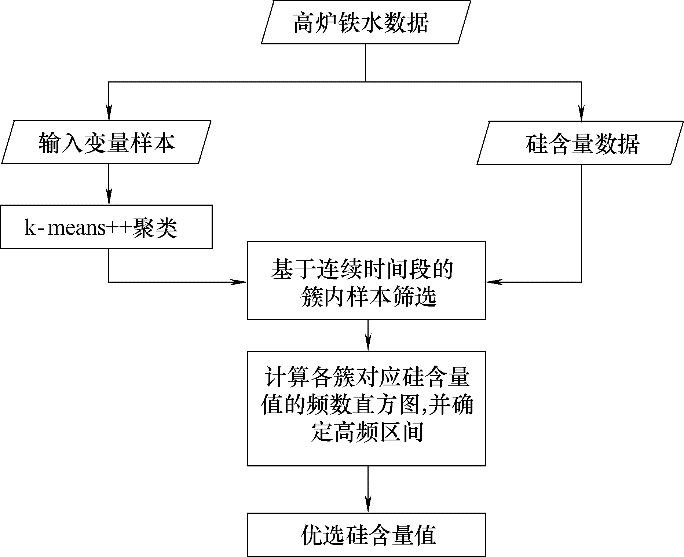
Fig.2 Flow chart of “k-means++ optimal selecting method”

Fig.3 Clusters of input variables by k-means++ for the first time

Fig.4 k-means ++ results after removing abnormal clusters
| 簇 | α | ρ | ||
|---|---|---|---|---|
| Cluster A | 5 | 366 | 393 | 0.93 |
| Cluster B | 5 | 109 | 129 | 0.84 |
| Cluster C | 5 | 17 | 26 | 0.65 |
| Cluster D | 5 | 103 | 116 | 0.89 |
| Cluster E | 3 | 45 | 71 | 0.63 |
Table 2 Statistics of each cluster
| 簇 | α | ρ | ||
|---|---|---|---|---|
| Cluster A | 5 | 366 | 393 | 0.93 |
| Cluster B | 5 | 109 | 129 | 0.84 |
| Cluster C | 5 | 17 | 26 | 0.65 |
| Cluster D | 5 | 103 | 116 | 0.89 |
| Cluster E | 3 | 45 | 71 | 0.63 |
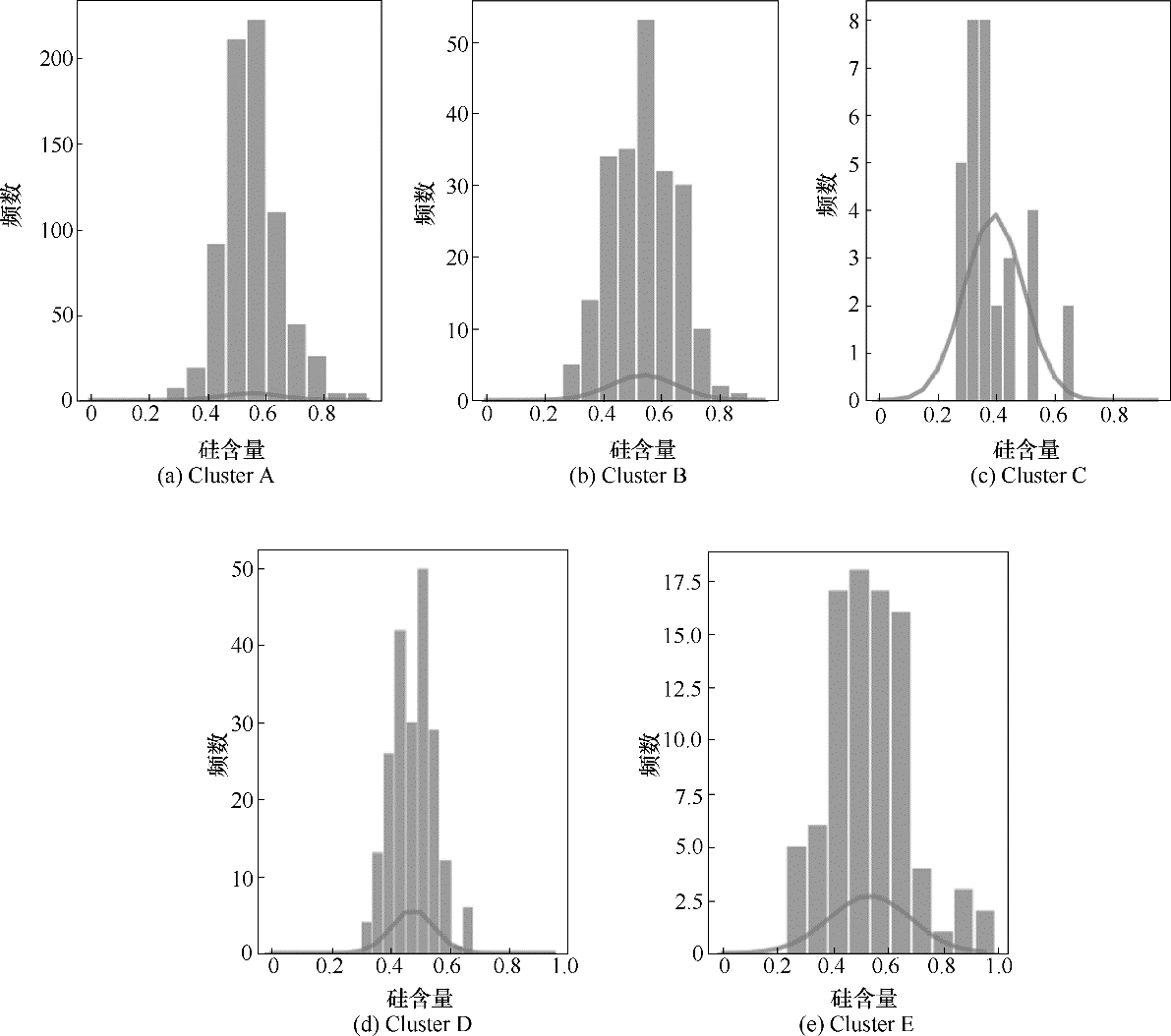
Fig.5 Frequency histogram of each cluster
| 样本周期内硅含量检测数目 | Cluster A | Cluster B | Cluster C | Cluster D | Cluster E | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | |
| 0 | 36 | 9.84% | 11 | 10.10% | 2 | 11.80% | 11 | 10.70% | 5 | 11.10% |
| 1 | 96 | 26.20% | 25 | 22.90% | 6 | 35.30% | 19 | 18.50% | 10 | 22.20% |
| 2 | 113 | 30.90% | 38 | 34.90% | 3 | 17.70% | 40 | 38.80% | 16 | 35.60% |
| 3 | 83 | 22.70% | 26 | 23.90% | 4 | 23.50% | 23 | 22.30% | 10 | 22.20% |
| 4 | 27 | 7.38% | 8 | 7.34% | 2 | 11.80% | 7 | 6.80% | 3 | 6.67% |
| 5 | 10 | 2.73% | 1 | 0.92% | 0 | 0 | 2 | 1.94% | 1 | 2.22% |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.97% | 0 | 0 |
| 9 | 1 | 0.27% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
Table 3 Proportion of silicon content of each cluster in different sample periods
| 样本周期内硅含量检测数目 | Cluster A | Cluster B | Cluster C | Cluster D | Cluster E | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | 样本数 | 占比 | |
| 0 | 36 | 9.84% | 11 | 10.10% | 2 | 11.80% | 11 | 10.70% | 5 | 11.10% |
| 1 | 96 | 26.20% | 25 | 22.90% | 6 | 35.30% | 19 | 18.50% | 10 | 22.20% |
| 2 | 113 | 30.90% | 38 | 34.90% | 3 | 17.70% | 40 | 38.80% | 16 | 35.60% |
| 3 | 83 | 22.70% | 26 | 23.90% | 4 | 23.50% | 23 | 22.30% | 10 | 22.20% |
| 4 | 27 | 7.38% | 8 | 7.34% | 2 | 11.80% | 7 | 6.80% | 3 | 6.67% |
| 5 | 10 | 2.73% | 1 | 0.92% | 0 | 0 | 2 | 1.94% | 1 | 2.22% |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0.97% | 0 | 0 |
| 9 | 1 | 0.27% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 簇 | 可匹配样本数 | 占比/% | |
|---|---|---|---|
| Cluster A | 116 | 98 | 84.48 |
| Cluster B | 129 | 101 | 78.29 |
| Cluster C | 393 | 457 | 124.86 |
| Cluster D | 71 | 59 | 83.1 |
| Cluster E | 26 | 16 | 61.54 |
Table 4 Statistics of samples which can be matched by the silicon content in the high-frequency interval
| 簇 | 可匹配样本数 | 占比/% | |
|---|---|---|---|
| Cluster A | 116 | 98 | 84.48 |
| Cluster B | 129 | 101 | 78.29 |
| Cluster C | 393 | 457 | 124.86 |
| Cluster D | 71 | 59 | 83.1 |
| Cluster E | 26 | 16 | 61.54 |
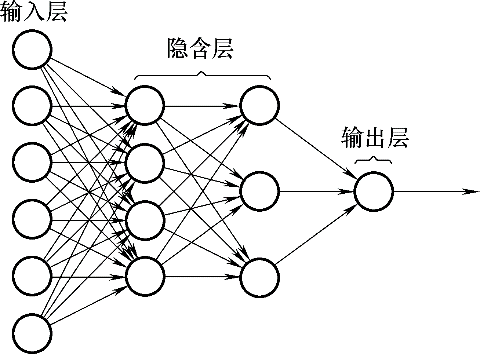
Fig.6 Multi-layer perceptron network structure
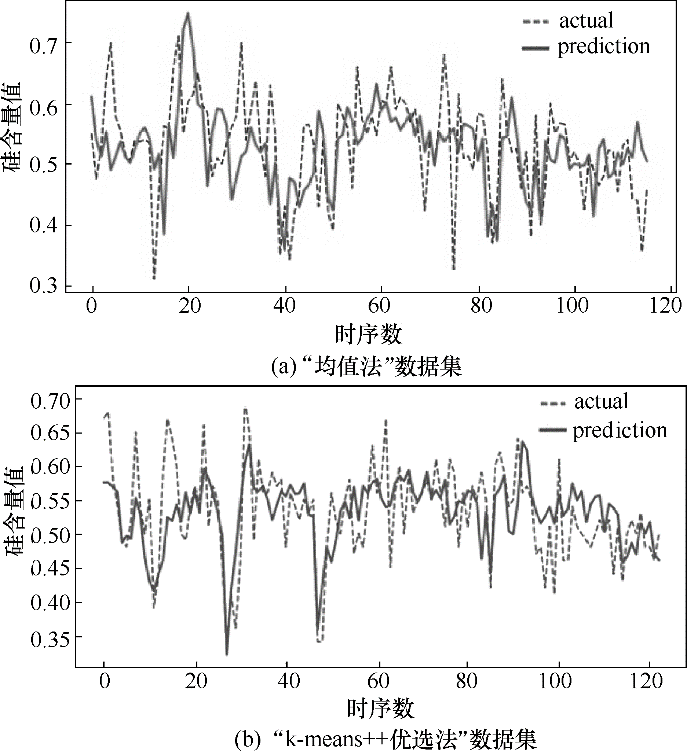
Fig.7 Comparison between the prediction and the actual value based on the multi-layer perceptron model
| 方法 | MSE | HR(0.05%) | HR(0.1%) | TAR |
|---|---|---|---|---|
| 均值法 | 0.0070 | 46.67% | 81.06% | 49.24% |
| k-means++优选法 | 0.0036 | 61.50% | 90.61% | 51.02% |
Table 5 Comparison between the data sets of “k-means++ optimal selection method” and “averaging method” based on the multi-layer perceptron model
| 方法 | MSE | HR(0.05%) | HR(0.1%) | TAR |
|---|---|---|---|---|
| 均值法 | 0.0070 | 46.67% | 81.06% | 49.24% |
| k-means++优选法 | 0.0036 | 61.50% | 90.61% | 51.02% |
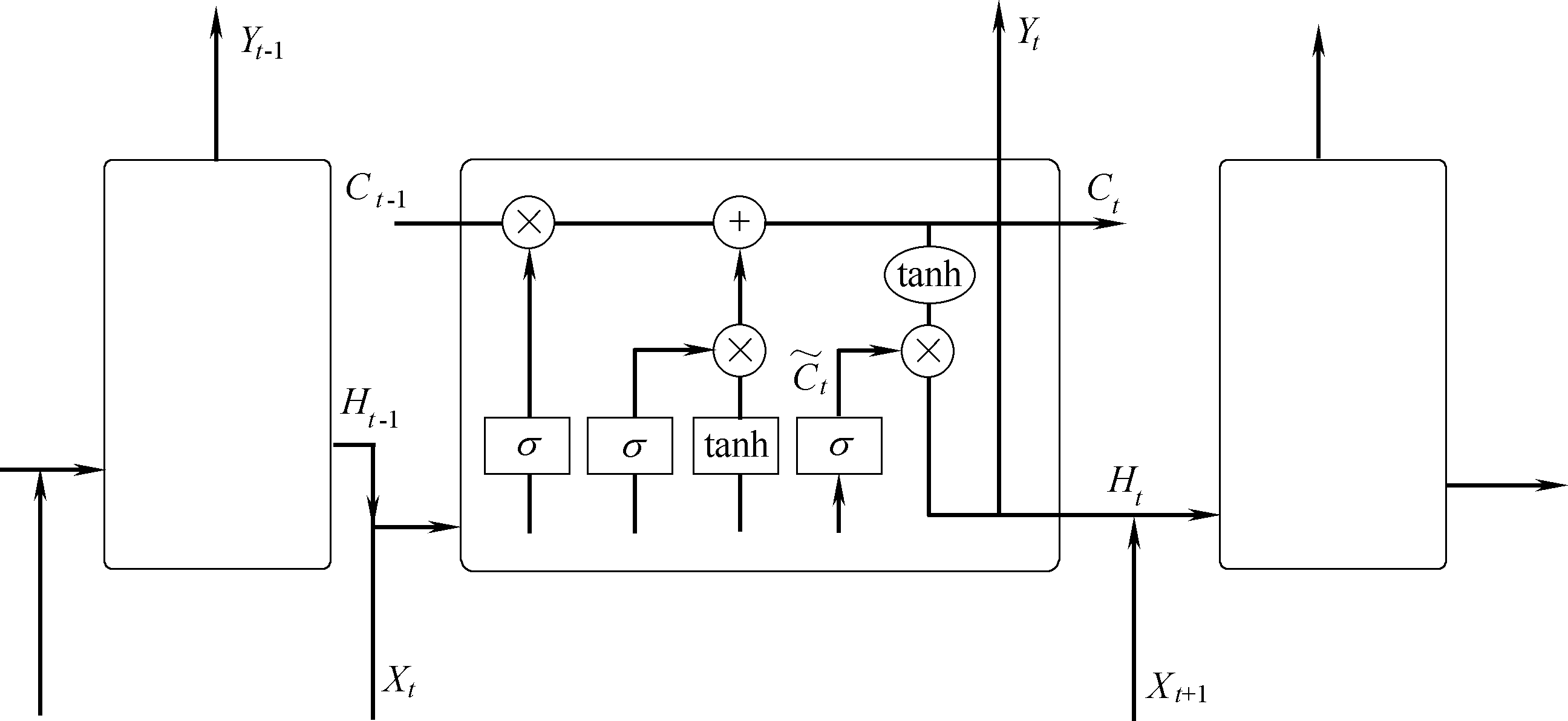
Fig.8 LSTM network structure
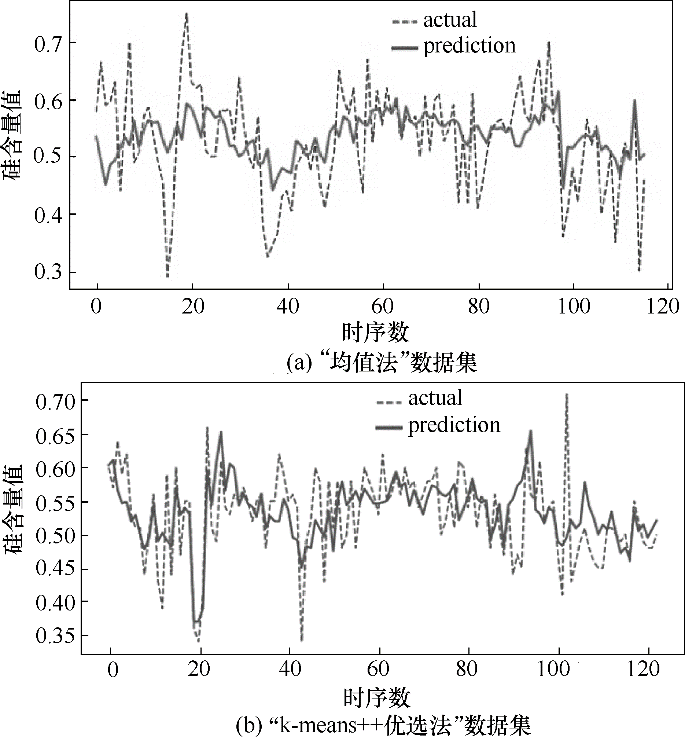
Fig.9 Comparison between the prediction and the actual value based on the LSTM network structure
| 方法 | MSE | HR(0.05%) | HR(0.1%) | TAR |
|---|---|---|---|---|
| 均值法 | 0.0066 | 48.94% | 81.52% | 55.30% |
| k-means++优选法 | 0.0027 | 67.02% | 94.15% | 57.82% |
Table 6 Comparison between the data sets of “k-means++ optimal selection method” and “averaging method” based on the LSTM network structure
| 方法 | MSE | HR(0.05%) | HR(0.1%) | TAR |
|---|---|---|---|---|
| 均值法 | 0.0066 | 48.94% | 81.52% | 55.30% |
| k-means++优选法 | 0.0027 | 67.02% | 94.15% | 57.82% |
| 1 | 尹菊萍, 蒋朝辉. 基于数据的高炉铁水硅含量预测[J]. 有色冶金设计与研究, 2015, 36(3): 36-38+41. |
| Yin J P, Jiang Z H. Prediction for blast furnace silicon content in hot metal based on data[J]. Nonferrous Metals Engineering & Research, 2015, 36(3): 36-38+41. | |
| 2 | 李泽龙, 杨春节, 刘文辉, 等. 基于LSTM-RNN模型的铁水硅含量预测[J]. 化工学报, 2018, 69(3): 992-997. |
| Li Z L, Yang C J, Liu W H, et al. Research on hot metal Si-content prediction based on LSTM-RNN[J]. CIESC Journal, 2018, 69(3): 992-997. | |
| 3 | Jian L, Gao C, Xia Z. A sliding‐window smooth support vector regression model for nonlinear blast furnace system[J]. Steel Research International, 2015, 82(3):169-179. |
| 4 | Xu X, Hua C, Tang Y, et al. Modeling of the hot metal silicon content in blast furnace using support vector machine optimized by an improved particle swarm optimizer[J]. Neural Computing and Applications, 2016, 27(6): 1451-1461. |
| 5 | Han Y, Li J, Yang X L, et al. Dynamic prediction research of silicon content in hot metal driven by big data in blast furnace smelting process under Hadoop cloud platform[J]. Complexity, 2018, 2018: 1-16. |
| 6 | Chen W, Wang B X, Han H L. Prediction and control for silicon content in pig iron of blast furnace by integrating artificial neural network with genetic algorithm[J]. Ironmaking & Steelmaking, 2013, 37(6): 458-463. |
| 7 | Luo S, Gao C, Zeng J, et al. Blast furnace system modeling by multivariate phase space reconstruction and neural networks[J]. Asian Journal of Control, 2013, 15(2): 553-561. |
| 8 | 尹林子, 李乐, 蒋朝辉. 基于粗糙集理论与神经网络的铁水硅含量预测[J]. 钢铁研究学报, 2019,31(8): 689-695. |
| Yin L Z, Li L, Jiang Z H. Prediction of silicon content in hot metal using neural network and rough set theory[J]. Journal of Iron and Steel Research, 2019, 31(8): 689-695. | |
| 9 | 刘家奇, 赵原, 杨文韬, 等. 基于BP神经网络的硅含量动态预测模型[J]. 中国战略新兴产业, 2017, (28): 92. |
| Liu J Q, Zhao Y, Yang W T, et al. Dynamic prediction model of silicon content based on BP neural network[J]. China Strategic Emerging Industry, 2017, (28): 92. | |
| 10 | 文冰洁, 吴胜利, 周恒, 等. 基于BP神经网络的COREX铁水硅含量预测模型[J]. 钢铁研究学报, 2018, 30(10): 776-781. |
| Wen B J, Wu S L, Zhou H, et al. A BP neural network based mathematical model for predicting Si content in hot metal from COREX process[J]. Journal of Iron and Steel Research, 2018, 30(10): 776-781. | |
| 11 | Zeng J S, Gao C H, Liu X G, et al. Using non‐linear GARCH model to predict silicon content in blast furnace hot metal[J]. Asian Journal of Control, 2010, 10(6): 632-637. |
| 12 | Henrik S, Frank P, Kiran G. Evolving nonlinear time-series models of the hot metal silicon content in the blast furnace[J]. Advanced Manufacturing Processes, 2007, 22(5): 8. |
| 13 | Su X L. Prediction of hot metal silicon content for blast furnace based on multi-layer online sequential extreme learning machine[C]// Proceedings of the 37th Chinese Control Conference(E). China: Technical Committee on Control Theory (TCCT), Chinese Association of Automation (CAA), 2018: 8025-8030. |
| 14 | Yang Y, Zhang S, Yin Y. A modified ELM algorithm for the prediction of silicon content in hot metal[J]. Neural Computing and Applications, 2016, 27(1): 241-247. |
| 15 | Ping Z, Meng Y, Hong W, et al. Data-driven dynamic modeling for prediction of molten iron silicon content using ELM with self-feedback[J]. Mathematical Problems in Engineering, 2015, 2015: 1-11. |
| 16 | 蒋朝辉, 董梦林, 桂卫华, 等. 基于Bootstrap的高炉铁水硅含量二维预报[J]. 自动化学报, 2016, 42(5): 715-723. |
| Jiang Z H, Dong M L, Gui W H, et al. Two-dimensional prediction for silicon content of hot metal of blast furnace based on Bootstrap[J]. Acta Automatica Sinica, 2016, 42(5): 715-723. | |
| 17 | 崔桂梅, 侯佳, 高翠玲, 等. 基于多传感器的高炉炼铁操作参数优化[J]. 传感器与微系统, 2015, 34(3): 21-23+27. |
| Cui G M, Hou J, Gao C L, et al. Optimization of operational parameters of BF iron-making based on multi-sensor[J]. Transducer and Microsystem Technologies, 2015, 34(3): 21-23+27. | |
| 18 | 崔桂梅, 李静, 张勇, 等. 高炉铁水温度的多元时间序列建模和预测[J]. 钢铁研究学报, 2014, 26(4): 33-37. |
| Cui G M, Li J, Zhang Y, et al. Multivariate time series modeling research for blast furnace hot iron temperature[J]. Journal of Iron and Steel Research, 2014, 26(4): 33-37. | |
| 19 | 李军朋. 高炉冶炼过程的铁水硅含量分析及其建模研究[D]. 秦皇岛: 燕山大学, 2015. |
| Li J P. Analysis and modeling research on hot metal silicon content of blast furnace smelting process[D]. Qinhuangdao: Yanshan University, 2015. | |
| 20 | 金勇进. 缺失数据的插补调整[J]. 数理统计与管理, 2010, 20(5): 47-53. |
| Jin Y J. Imputation adjustment method for missing data[J]. Journal of Applied Statistics and Management, 2010, 20(5): 47-53. | |
| 21 | 吴金花. 高炉冶炼过程分析及其铁水硅含量预测模型研究[D]. 秦皇岛: 燕山大学, 2016. |
| Wu J H. The analysis on blast furnace smelting process and research on hot metal silicon content prediction model[D]. Qinhuangdao: Yanshan University, 2016. | |
| 22 | 赵哲, 张勇, 于楠楠, 等. 面向铁水温度的高炉异常数据检测及修补[J]. 自动化与仪表, 2015, 30(2): 63-67. |
| Zhao Z, Zhang Y, Yu N N, et al. Furnace temperature modelling and data processing for blast furnace object oriented hot metal temperature[J]. Automation & Instrumentation, 2015, 30(2): 63-67. | |
| 23 | 谷海彤, 陈邵华, 吴晓强, 等. DA多重插补法在电网电能量数据缺失处理中的应用[J]. 广西科技大学学报, 2017, 28(3): 103-109. |
| Gu H T, Chen S H,Wu X Q, et al. Application of DA multiple interpolation in electric energy data missing[J]. Journal of Guangxi University of Science and Technology, 2017, 28(3): 103-109. | |
| 24 | 程豪. 逆概率加权多重插补法在中国居民收入影响因素中的应用研究[J]. 统计与信息论坛, 2019, 34(7): 26-34. |
| Cheng H. An application research of inverse probability weighted multiple imputation method on factors of residents income in China[J]. Statistics & Information Forum, 2019, 34(7): 26-34. | |
| 25 | 丛亚. 面向多采样率数据的工业过程故障检测[D]. 杭州: 浙江大学, 2018. |
| Cong Y. Fault detection for industrial process oriented to multi-rate data[D]. Hangzhou: Zhejiang University, 2018. | |
| 26 | 李志军, 梁乐乐, 韩存武, 等. 基于PLS的多采样率过程故障检测及其仿真[J]. 计算机仿真, 2016, 33(10): 445-449. |
| Li Z J, Liang L L, Han C W, et al. Multi-rate process fault detection based on partial least squares[J]. Computer Simulation,2016, 33(10): 445-449. | |
| 27 | 宋菁华. 高炉冶炼过程的多尺度特性与硅含量预测方法研究[D]. 杭州: 浙江大学, 2016. |
| Song J H. Application of improved EMD-Elman neural network to predict silicon content in hot metal[D]. Hangzhou: Zhejiang University, 2016. | |
| 28 | Chu Y, Gao C. Data-based multiscale modeling for blast furnace system[J]. AIChE Journal, 2014, 60(6): 2197-2210. |
| 29 | 刘敏. 基于模糊模型的高炉硅含量研究及预测[D]. 包头: 内蒙古科技大学, 2012. |
| Liu M. Research and prediction of Si content in blast furnace based on fuzzy model[D]. Baotou: Inner Mongolia University of Science and Technology, 2012. | |
| 30 | 谢灵杰, 高小强, 郑忠, 等. 高炉铁水硅含量自组织预测中的模式量化[J]. 钢铁研究学报, 2004, 16(4): 68-71. |
| Xie L J, Gao X Q, Zheng Z, et al. Pattern classification of model for predicting silicon content in hot metal based on self-organized experience evolution[J]. Journal of Iron and Steel Research, 2004, 16(4): 68-71. | |
| 31 | 谢玮, 毕臣臣, 刘学清, 等. 基于PCA-Kmeans++的煤层气多属性融合聚类分析方法研究[J]. 煤炭技术, 2019, 38(5): 53-56. |
| Xie W, Bi C C, Liu X Q, et al. Cluster analysis method for multi-attribute fusion of coalbed methane based on PCA-Kmeans++[J]. Coal Technology, 2019, 38(5): 53-56. | |
| 32 | Zhou P, Yuan M, Wang H, et al. Multivariable dynamic modeling for molten iron quality using online sequential random vector functional-link networks with self-feedback connections[J]. Information Sciences, 2015, 325(20): 237-255. |
| 33 | 赵莉, 侯兴哲, 胡君, 等. 基于改进k-means算法的海量智能用电数据分析[J]. 电网技术, 2014, 38(10): 2715-2720. |
| Zhao L, Hou X Z, Hu J, et al. Improved k-means algorithm based analysis on massive data of intelligent power utilization[J]. Power System Technology, 2014, 38(10): 2715-2720. | |
| 34 | 张荣, 李伟平, 莫同. 深度学习研究综述[J]. 信息与控制, 2018, 47(4): 5-17+30. |
| Zhang R, Li W P, Mo T. Review of deep learning[J]. Information and Control, 2018, 47(4): 5-17+30. |
| [1] | Kaijie WEN, Li GUO, Zhaojie XIA, Jianhua CHEN. A rapid simulation method of gas-solid flow by coupling CFD and deep learning [J]. CIESC Journal, 2023, 74(9): 3775-3785. |
| [2] | Gang YIN, Yihui LI, Fei HE, Wenqi CAO, Min WANG, Feiya YAN, Yu XIANG, Jian LU, Bin LUO, Runting LU. Early warning method of aluminum reduction cell leakage accident based on KPCA and SVM [J]. CIESC Journal, 2023, 74(8): 3419-3428. |
| [3] | Linqi YAN, Zhenlei WANG. Multi-step predictive soft sensor modeling based on STA-BiLSTM-LightGBM combined model [J]. CIESC Journal, 2023, 74(8): 3407-3418. |
| [4] | Yuying GUO, Jiaqiang JING, Wanni HUANG, Ping ZHANG, Jie SUN, Yu ZHU, Junxuan FENG, Hongjiang LU. Water-lubricated drag reduction and pressure drop model modification for heavy oil pipeline [J]. CIESC Journal, 2023, 74(7): 2898-2907. |
| [5] | Weiming SHAO, Wenxue HAN, Wei SONG, Yong YANG, Can CHEN, Dongya ZHAO. Dynamic soft sensor modeling method based on distributed Bayesian hidden Markov regression [J]. CIESC Journal, 2023, 74(6): 2495-2502. |
| [6] | Yanhui LI, Shaoming DING, Zhouyang BAI, Yinan ZHANG, Zhihong YU, Limei XING, Pengfei GAO, Yongzhen WANG. Corrosion micro-nano scale kinetics model development and application in non-conventional supercritical boilers [J]. CIESC Journal, 2023, 74(6): 2436-2446. |
| [7] | Yuan YU, Weiwei CHEN, Junjie FU, Jiaxiang LIU, Zhiwei JIAO. Study and prediction of flow field in the annular region of geometrically similar turbo air classifier [J]. CIESC Journal, 2023, 74(6): 2363-2373. |
| [8] | Xuejin GAO, Yuzhuo YAO, Huayun HAN, Yongsheng QI. Fault monitoring of fermentation process based on attention dynamic convolutional autoencoder [J]. CIESC Journal, 2023, 74(6): 2503-2521. |
| [9] | Cheng YUN, Qianlin WANG, Feng CHEN, Xin ZHANG, Zhan DOU, Tingjun YAN. Deep-mining risk evolution path of chemical processes based on community structure [J]. CIESC Journal, 2023, 74(4): 1639-1650. |
| [10] | Xinyuan WU, Qilei LIU, Boyuan CAO, Lei ZHANG, Jian DU. Group2vec: group vector representation and its property prediction applications based on unsupervised machine learning [J]. CIESC Journal, 2023, 74(3): 1187-1194. |
| [11] | Kenian SHI, Jingyuan ZHENG, Yu QIAN, Siyu YANG. Two-stage stochastic programming of steam power system based on Markov chain [J]. CIESC Journal, 2023, 74(2): 807-817. |
| [12] | Jiahui CHEN, Xinze YANG, Guzhong CHEN, Zhen SONG, Zhiwen QI. A critical discussion on developing molecular property prediction models: density of ionic liquids as example [J]. CIESC Journal, 2023, 74(2): 630-641. |
| [13] | Xuejin GAO, Kun CHENG, Huayun HAN, Huihui Gao, Yongsheng QI. Fault diagnosis of chillers using central loss conditional generative adversarial network [J]. CIESC Journal, 2022, 73(9): 3950-3962. |
| [14] | Jing YANG, Zhenkang LIN, Jun TANG, Cheng FAN, Kening SUN. A review of fault characteristics, fault diagnosis and identification for lithium-ion battery systems [J]. CIESC Journal, 2022, 73(8): 3394-3405. |
| [15] | Xinjie ZHOU, Jianlin WANG, Xingcong AI, Enguang SUI, Rutong WANG. IDPC-RVM based online prediction of quality variables for multimode batch processes [J]. CIESC Journal, 2022, 73(7): 3120-3130. |
| Viewed | ||||||
|
Full text |
|
|||||
|
Abstract |
|
|||||

