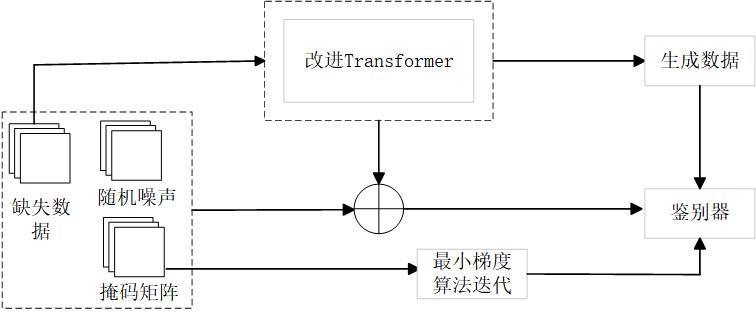
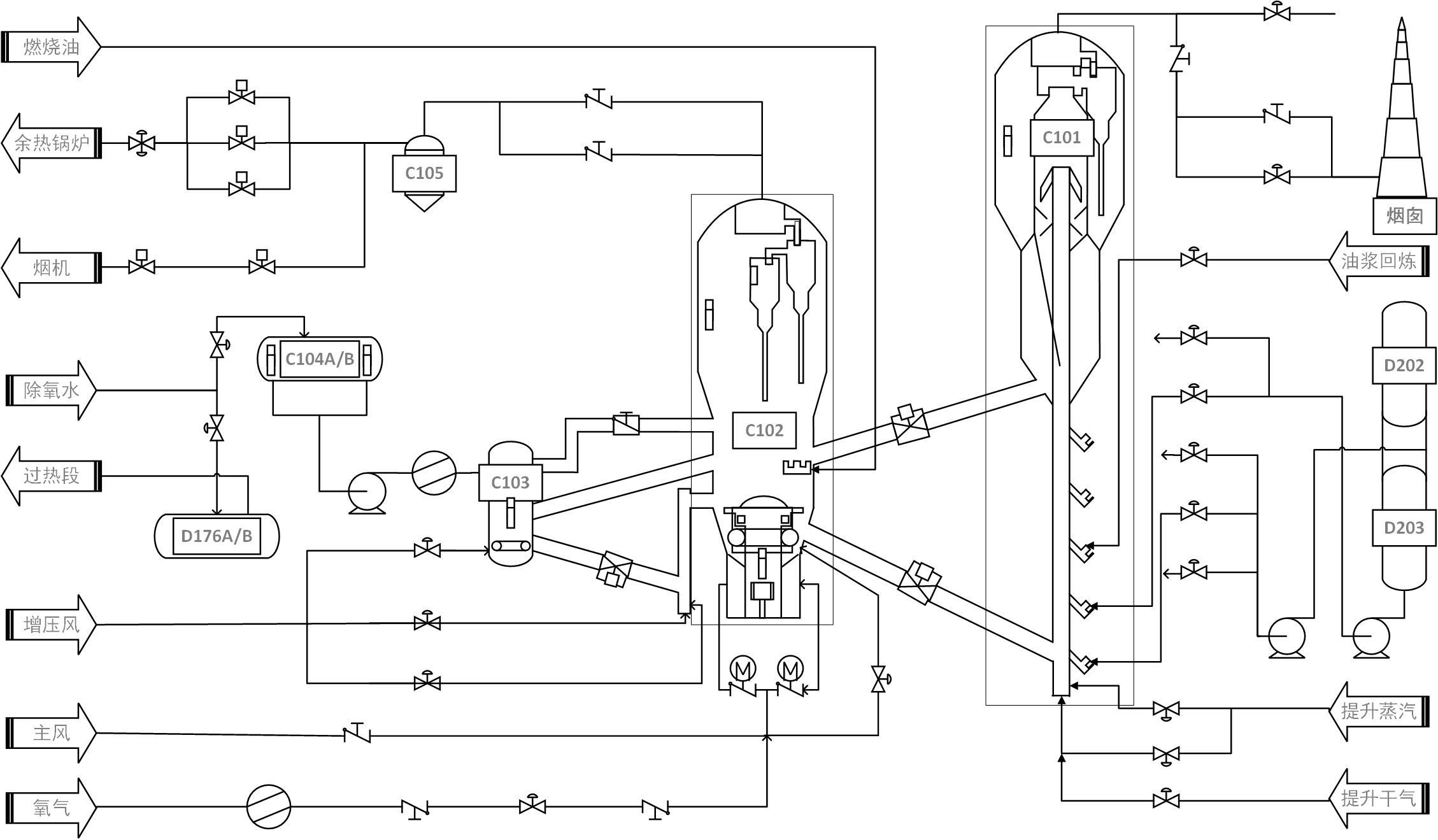
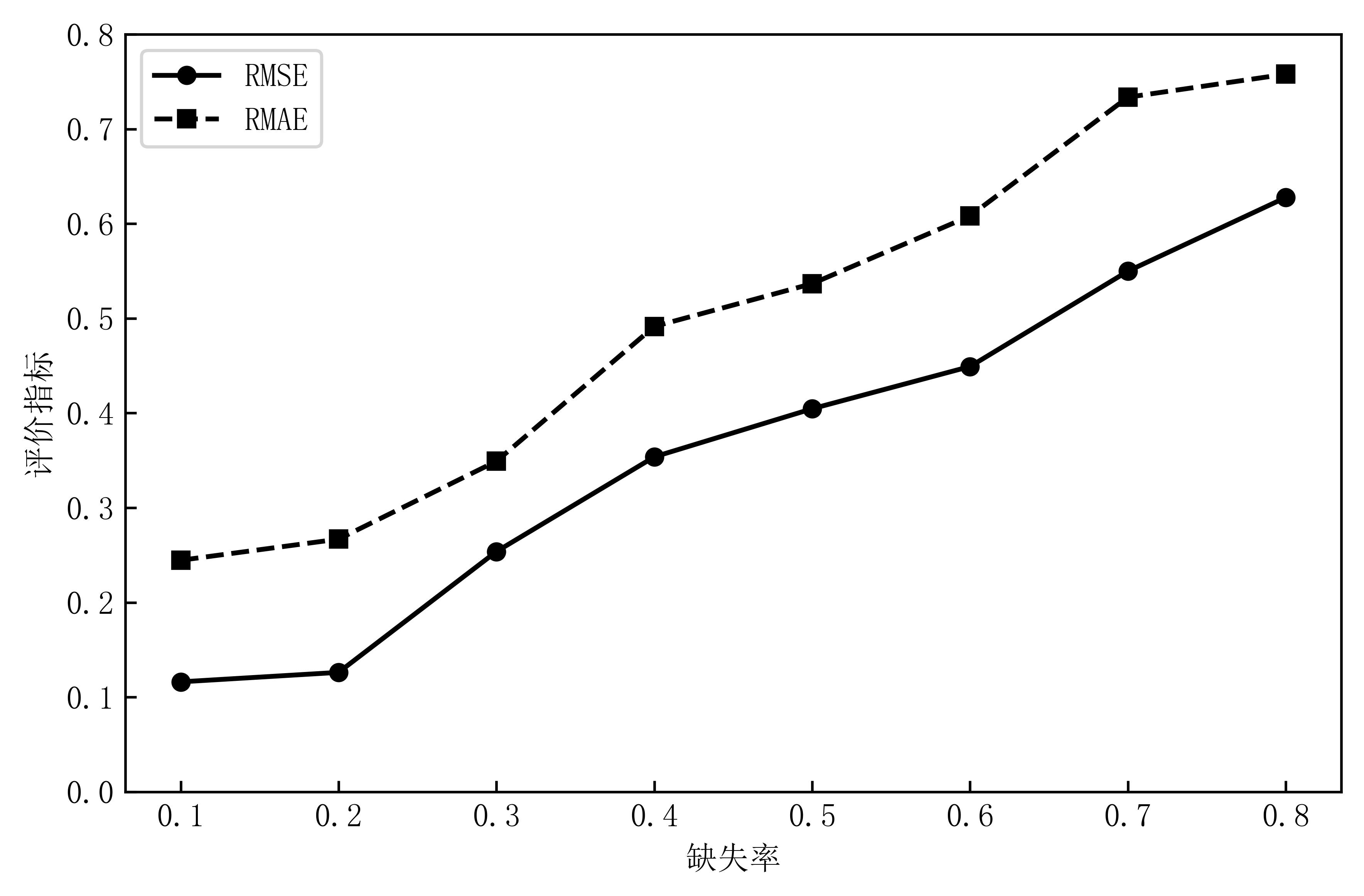
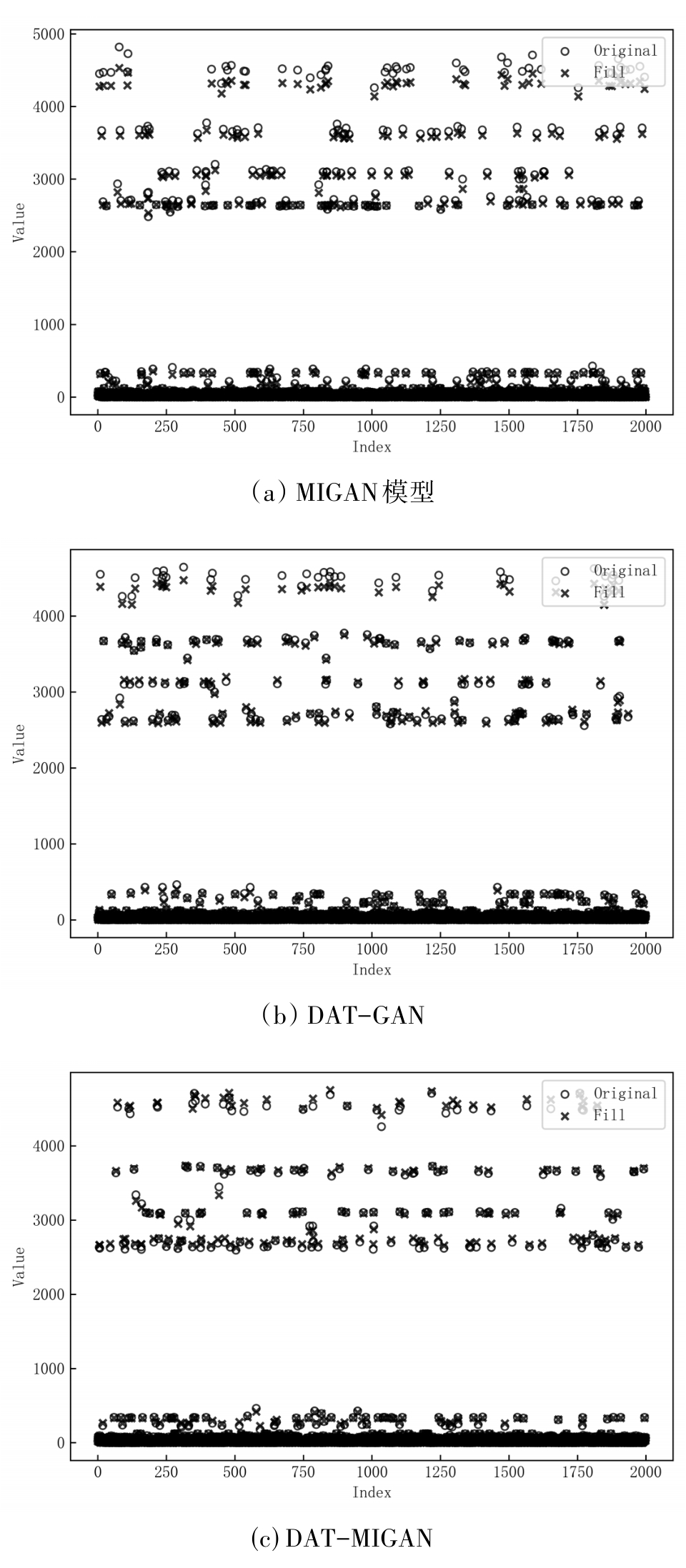
| [1] |
傅向升. 创新转型提质增效为中国式现代化作出石化产业的新贡献:在2024全国石油和化工行业经济形势分析会上的报告[J].中国石油和化工,2024(8):16-25.
|
|
Fu X S. Innovating, transforming, improving quality and increasing efficiency, making new contributions to Chinese modernization in petrochemical industry: report at the 2024 national economic situation analysis conference of petroleum and chemical industry[J]. China Petroleum and Chemical Industry, 2024(8): 16-25
|
| [2] |
黄苏.化工安全生产问题与事故防范策略[J].中国石油和化工标准与质量,2023,43(22):15-17.
|
|
Huang S. Chemical safety production problems and accident prevention strategies[J]. China Petroleum and Chemical Standard and Quality, 2023, 43(22): 15-17.
|
| [3] |
张小萌.化工安全生产管理中的问题及应对策略[J].中国石油和化工标准与质量,2023, 43(22):72-74.
|
|
Zhang X M. Problems and countermeasures in chemical safety production management[J]. China Petroleum and Chemical Standard and Quality, 2023, 43(22): 72-74.
|
| [4] |
Zainuddin A, Hairuddin M A, Yassin A I M, et al. Time series data and recent imputation techniques for missing data: a review[C]//2022 International Conference on Green Energy, Computing and Sustainable Technology (GECOST). October 26-28, 2022, Miri Sarawak, Malaysia. IEEE, 2023: 346-350.
|
| [5] |
Yang B, Kang Y, Yuan Y Y, et al. ST-LBAGAN: Spatio-temporal learnable bidirectional attention generative adversarial networks for missing traffic data imputation[J]. Knowledge-Based Systems, 2021, 215: 106705.
|
| [6] |
Jeong S, Joo C, Lim J, et al. A novel graph-based missing values imputation method for industrial lubricant data[J]. Computers in Industry, 2023, 150: 103937.
|
| [7] |
Xu T C, Chen K, Li G. The more data, the better? Demystifying deletion-based methods in linear regression with missing data[J]. Statistics and Its Interface, 2022, 15(4): 515-526.
|
| [8] |
Khan S I, Hoque A S M L. SICE: an improved missing data imputation technique[J]. Journal of big Data, 2020, 7(1): 37.
|
| [9] |
Fang C G, Wang C. Time series data imputation: a survey on deep learning approaches[EB/OL]. 2020: arXiv: 2011.11347.
|
| [10] |
Sun Y G, Li J, Xu Y F, et al. Deep learning versus conventional methods for missing data imputation: a review and comparative study[J]. Expert Systems with Applications, 2023, 227: 120201.
|
| [11] |
Luo L, Fan Z Y, Chen Y M, et al. Cyclic Generative Adversarial Networks with KNN-transformers for missing traffic data completion[J]. Applied Soft Computing, 2024, 167: 112406.
|
| [12] |
Li H Z, Liao Y L, Tian Z J, et al. Bidirectional stackable recurrent generative adversarial imputation network for specific emitter missing data imputation[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 2967-2980.
|
| [13] |
Tak S, Woo S, Yeo H. Data-driven imputation method for traffic data in sectional units of road links[J]. IEEE Transactions on Intelligent Transportation Systems, 2016, 17(6): 1762-1771.
|
| [14] |
Deepa P, Gunavathi C. A Novel Aggregated Multiple Imputation Approach for Enhanced Survival Prediction and Classification on Breast Cancer and Lung Cancer Data[J]. IEEE Access, 2024, 12: 189102-189121.
|
| [15] |
Zhang J L, Yuan X F, Wang K, et al. AMING: Adaptive-Learning Mechanism Based Missing-Value Imputation Networks Using GAN in Industrial Processes[C]//2024 IEEE 13th Data Driven Control and Learning Systems Conference (DDCLS) . May 17-19, 2024, Kaifeng, China. IEEE,2024: 257-262
|
| [16] |
Lee S Y, Connerton T P, Lee Y W, et al. Semi-GAN: An improved GAN-based missing data imputation method for the semiconductor industry[J]. IEEE Access, 2022, 10: 72328-72338.
|
| [17] |
Kang M Y, Zhu R, Chen D X, et al. CM-GAN: a cross-modal generative adversarial network for imputing completely missing data in digital industry[J]. IEEE Transactions on Neural Networks and Learning Systems, 2024, 35(3): 2917-2926.
|
| [18] |
Wu H X, Xu J H, Wang J M, et al. Autoformer: decomposition transformers with auto-correlation for long-term series forecasting[C]//Neural Information Processing Systems., 2021
|
| [19] |
Zhou H Y, Zhang S H, Peng J Q, et al. Informer: beyond efficient transformer for long sequence time-series forecasting[J]. Proceedings of the AAAI Conference on Artificial Intelligence, 2021, 35(12): 11106-11115.
|
| [20] |
Yoon N, Kim H. DMGAN: bridging AI and chemistry with enhanced GC-MS data generation[C]//2024 IEEE SENSORS. October 20-23, 2024, Kobe, Japan. IEEE, 2024: 1-4.
|
| [21] |
Chen Z H, Zhu L J, Lu H, et al. Research on bearing fault diagnosis based on improved genetic algorithm and BP neural network[J]. Scientific Reports, 2024, 14: 15527.
|
| [22] |
Li J M, Yao X F, Wang X D, et al. Multiscale local features learning based on BP neural network for rolling bearing intelligent fault diagnosis[J]. Measurement, 2020, 153: 107419.
|
| [23] |
魏微. 基于深度学习的石化缺失数据填充与故障诊断方法研究[D]. 北京: 北京化工大学, 2025.
|
|
Wei W. Research on the method of filling missing data and fault diagnosis in petrochemical industry based on deep learning[D]. Beijing: Beijing University of Chemical Technology, 2025.
|
| [24] |
Yao Z J, Zhao C H. FIGAN: a missing industrial data imputation method customized for soft sensor application[J]. IEEE Transactions on Automation Science and Engineering, 2022, 19(4): 3712-3722.
|
| [25] |
Wang S Y, Li W G, Hou S Y, et al. STA-GAN: a spatio-temporal attention generative adversarial network for missing value imputation in satellite data[J]. Remote Sensing, 2023, 15(1): 88.
|
| [26] |
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[C]Advances in Neural Information Processing Systems. 2017: 5998–6008.
|
| [27] |
Devlin J, Chang M W, Lee K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[EB/OL]. 2018: arXiv: 1810.04805.
|
| [28] |
Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: transformers for image recognition at scale[EB/OL]. 2020: arXiv: 2010.11929.
|
| [29] |
YIN S, DING S X, HAGHANI A,et al. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process[J].Journal of Process Control,2012,22(9): 1567-1581.
|
| [30] |
周乐, 刘昕明, 周鹤龄. CPSO-NP优化算法及其在TE过程中应用[J]. 测控技术, 2018(7): 32-36, 41.
|
|
Zhou L, Liu X M, Zhou H L. Chaotic particle swarm optimization with natural selection and predatory search(CPSO-NP) and its application in TE process[J]. Measurement & Control Technology, 2018(7): 32-36, 41.
|
| [31] |
陈雨, 韩永明, 王尊, 等. 基于数据复杂网络理论的系统故障检测方法[J]. 化工学报, 2014, 65(11): 4503-4508.
|
|
Chen Y, Han Y M, Wang Z, et al. System fault detection based on data-driven and complex networks theory[J]. CIESC Journal, 2014, 65(11): 4503-4508.
|
 ), 李嘉骏1,2, 魏微1,2, 韩永明1,2, 胡渲1,2, 王孟志1,2(
), 李嘉骏1,2, 魏微1,2, 韩永明1,2, 胡渲1,2, 王孟志1,2( 京公网安备 11010102001995号
京公网安备 11010102001995号