| 1 |
徐海丰.全球乙烯产业格局变化及发展前景分析[J].国际石油经济, 2023, 31(1): 65-70, 82.
|
|
Xu H F. The change and development prospect of global ethylene industry[J]. International Petroleum Economics, 2023, 31(1): 65-70, 82.
|
| 2 |
陆浩.我国乙烯工业及下游产业链发展现状与展望[J]. 当代石油石化, 2022, 30(4): 22-27.
|
|
Lu H. Development status and prospect of China’s ethylene industry chain[J]. Petroleum & Petrochemical Today, 2022, 30(4): 22-27.
|
| 3 |
刘春平, 王昕, 王振雷. 基于相关积分优化方法的裂解炉优化[J]. 化工学报, 2015, 66(10): 4067-4075.
|
|
Liu C P, Wang X, Wang Z L. Optimization of cracking furnace based on correlation integral optimal method[J]. CIESC Journal, 2015, 66(10): 4067-4075.
|
| 4 |
Wang T, Ye Z C, Wang X J, et al. Improved distributed optimization algorithm and its application in energy saving of ethylene plant[J]. Chemical Engineering Science, 2022, 251: 117449.
|
| 5 |
耿志强, 毕帅, 王尊, 等. 基于改进NSGA-Ⅱ算法的乙烯裂解炉操作优化[J]. 化工学报, 2020, 71(3): 1088-1094.
|
|
Geng Z Q, Bi S, Wang Z, et al. Operation optimization of ethylene cracking furnace based on improved NSGA-Ⅱ algorithm[J]. CIESC Journal, 2020, 71(3): 1088-1094.
|
| 6 |
Li C F, Zhu Q X, Geng Z Q. Multi-objective particle swarm optimization hybrid algorithm: an application on industrial cracking furnace[J]. Industrial & Engineering Chemistry Research, 2007, 46(11): 3602-3609.
|
| 7 |
严逍亚, 王振雷, 王昕. 多策略改进的土狼算法及工业应用[C/OL]//第31届中国过程控制会议(CPCC 2020)摘要集. 徐州, 2020: 59. .
|
|
Yan X Y, Wang Z L, Wang X. A hybrid strategy modified coyote optimization algorithm and its industrial application[C/OL]//TCPC, CAA. CPCC 2020 Summary Set. Xuzhou, 2020: 59. .
|
| 8 |
Nian X Y, Wang Z L, Qian F. A hybrid algorithm based on differential evolution and group search optimization and its application on ethylene cracking furnace[J]. Chinese Journal of Chemical Engineering, 2013, 21(5): 537-543.
|
| 9 |
黄一俞. 乙烯裂解炉过程建模与操作优化[D]. 北京: 北京化工大学, 2005.
|
|
Huang Y Y. Process modeling and operation optimization of ethylene cracking furnace[D]. Beijing: Beijing University of Chemical Technology, 2005.
|
| 10 |
王秋懿. 基于改进NNIA的乙烯裂解炉操作优化[D]. 北京: 北京化工大学, 2022.
|
|
Wang Q Y. Operation optimization of ethylene cracking furnace based on improved NNIA[D]. Beijing: Beijing University of Chemical Technology, 2022.
|
| 11 |
尚田丰, 耿志强. 基于GA-RBF网络的乙烯裂解炉在线操作优化[J]. 计算机与应用化学, 2009, 26(8): 1003-1007.
|
|
Shang T F, Geng Z Q. Online operation optimization in ethylene cracking furnace based on GA-RBF network[J]. Computers and Applied Chemistry, 2009, 26(8): 1003-1007.
|
| 12 |
Mnih V, Kavukcuoglu K, Silver D, et al. Human-level control through deep reinforcement learning[J]. Nature, 2015, 518(7540): 529-533.
|
| 13 |
Lillicrap T P, Hunt J J, Pritzel A, et al. Continuous control with deep reinforcement learning[EB/OL]. 2015. .
|
| 14 |
Fujimoto S, van Hoof H, Meger D. Addressing function approximation error in actor-critic methods[EB/OL]. 2018. .
|
| 15 |
Sutton R S, Barto A G. Reinforcement Learning: An Introduction[M]. Cambridge: MIT Press, 1998.
|
| 16 |
南栖仙策. 强化学习控制白皮书[R/OL]. 2022. .
|
|
POLIXIR 2022-RL-Control White Paper[R/OL]. 2022. .
|
| 17 |
Zhu L W, Cui Y D, Takami G, et al. Scalable reinforcement learning for plant-wide control of vinyl acetate monomer process[J]. Control Engineering Practice, 2020, 97: 104331.
|
| 18 |
Powell B K M, Machalek D, Quah T. Real-time optimization using reinforcement learning[J]. Computers & Chemical Engineering, 2020, 143: 107077.
|
| 19 |
洪博岩. 乙烯裂解炉平均COT温度先进控制系统的开发与应用[J]. 石油化工高等学校学报, 2019, 32(2): 92-97.
|
|
Hong B Y. Application and development of advanced control system of average COT temperature in the ethylene cracking furnace[J]. Journal of Petrochemical Universities, 2019, 32(2): 92-97.
|
| 20 |
Edwin E H, Arnesen T, Hugosson G I. Evaluation of thermal cracker operation by use of an infrared camera[J]. Proceedings of SPIE-The International Society for Optical Engineering, 1998, 3361(2): 125-136
|
| 21 |
Morales E F, Murrieta-Cid R, Becerra I, et al. A survey on deep learning and deep reinforcement learning in robotics with a tutorial on deep reinforcement learning[J]. Intelligent Service Robotics, 2021, 14(5): 773-805.
|
| 22 |
Bengio Y, Lodi A, Prouvost A. Machine learning for combinatorial optimization: a methodological tour d’horizon[J]. European Journal of Operational Research, 2021, 290(2): 405-421.
|
| 23 |
Plaat A. Deep Reinforcement Learning[M]. Singapore: Springer Nature Singapore, 2022.
|
| 24 |
Pan L, Cai Q P, Huang L B. Softmax deep double deterministic policy gradients[EB/OL]. 2020. .
|
| 25 |
Schulman J, Wolski F, Dhariwal P, et al. Proximal policy optimization algorithms[EB/OL]. 2017. .
|
 ), 王振雷(
), 王振雷( 京公网安备 11010102001995号
京公网安备 11010102001995号



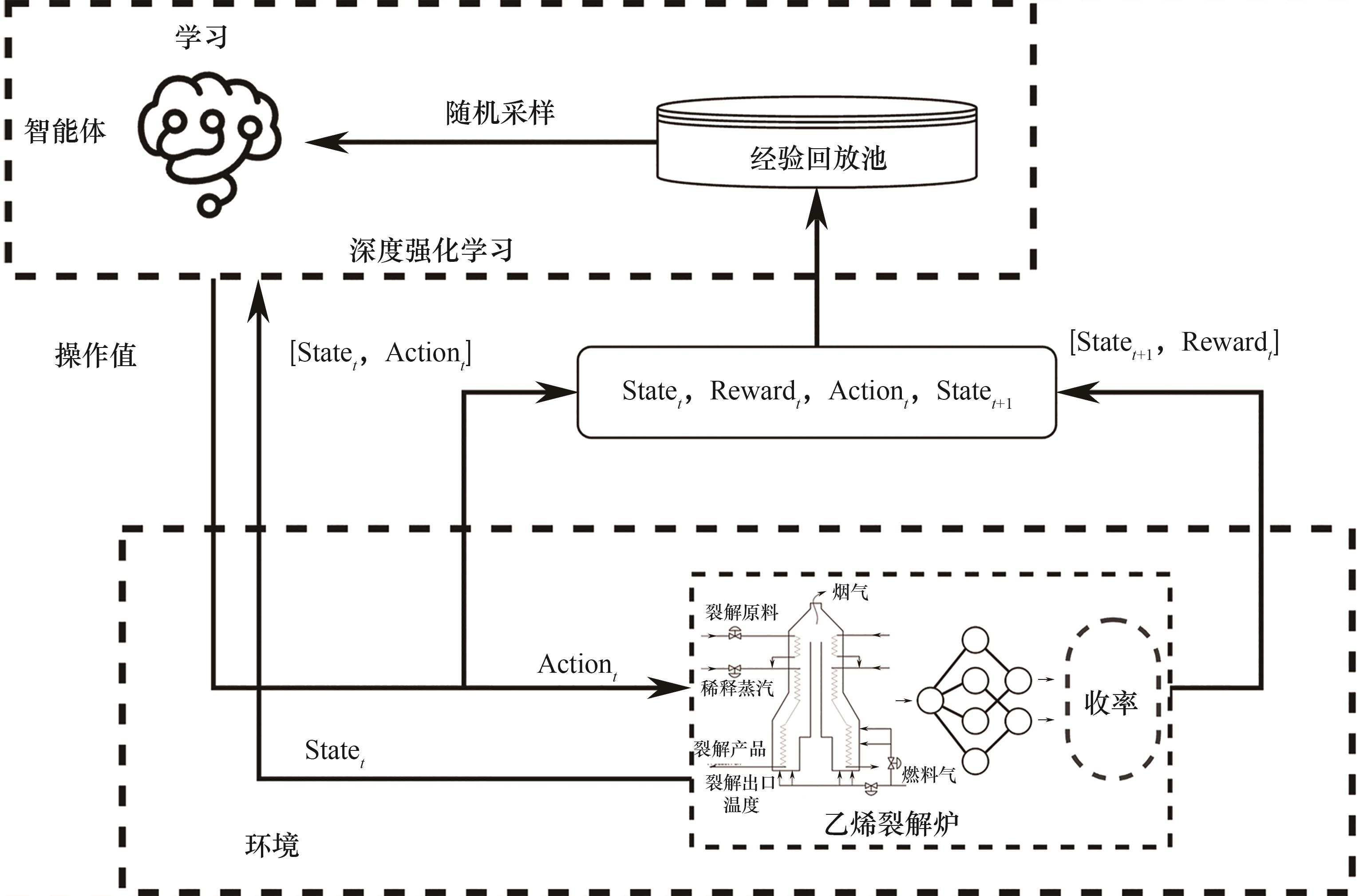
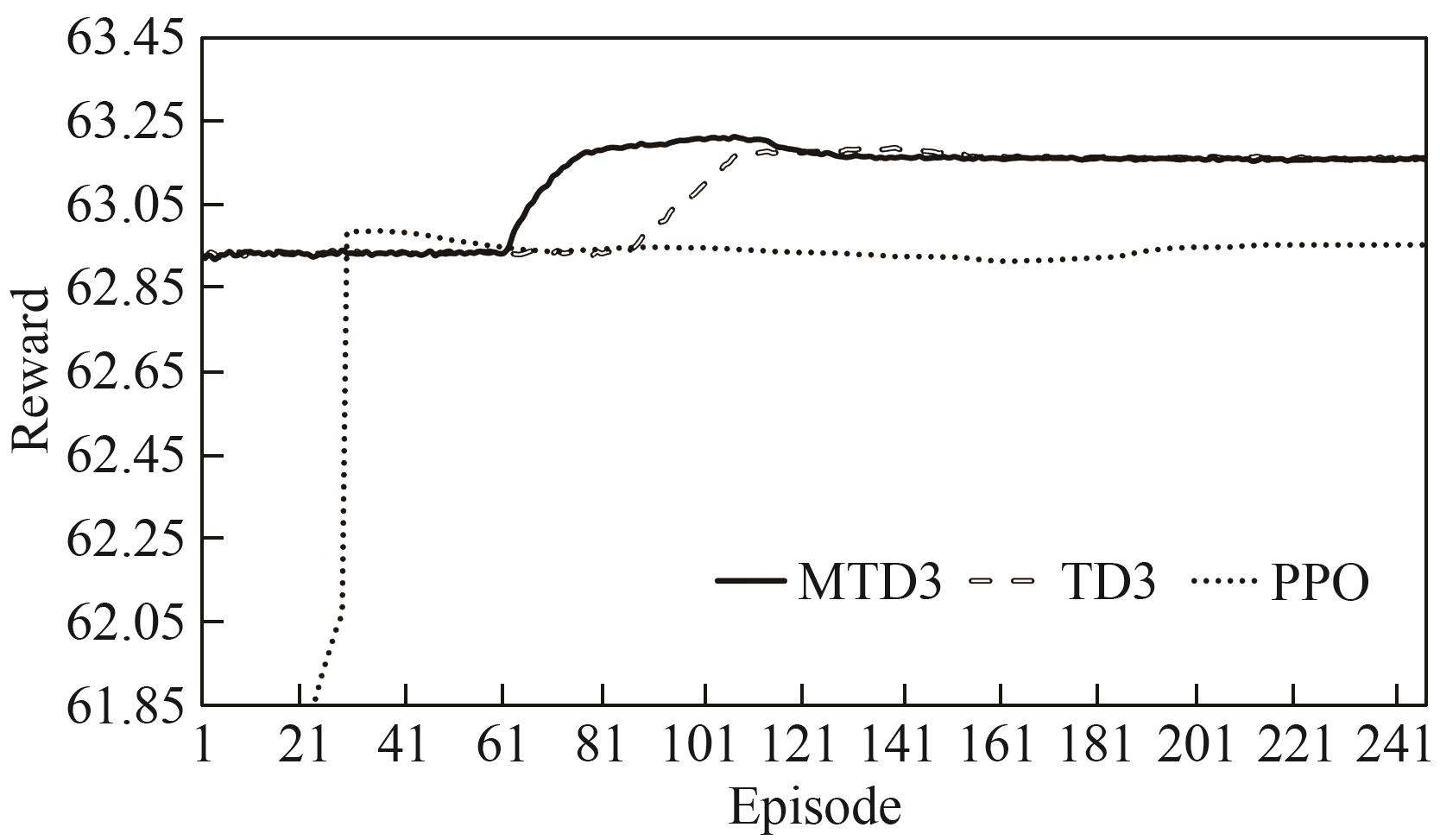
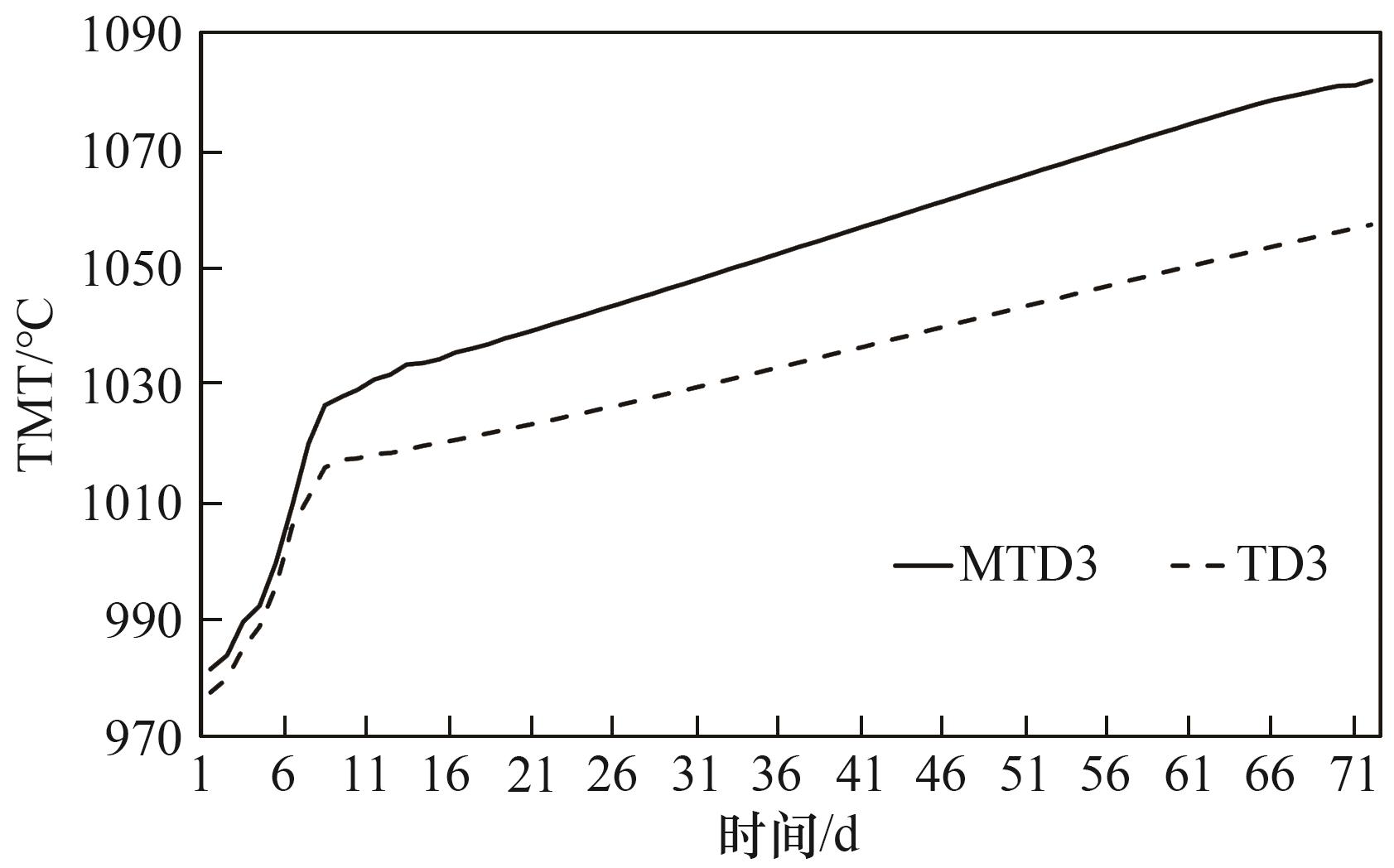
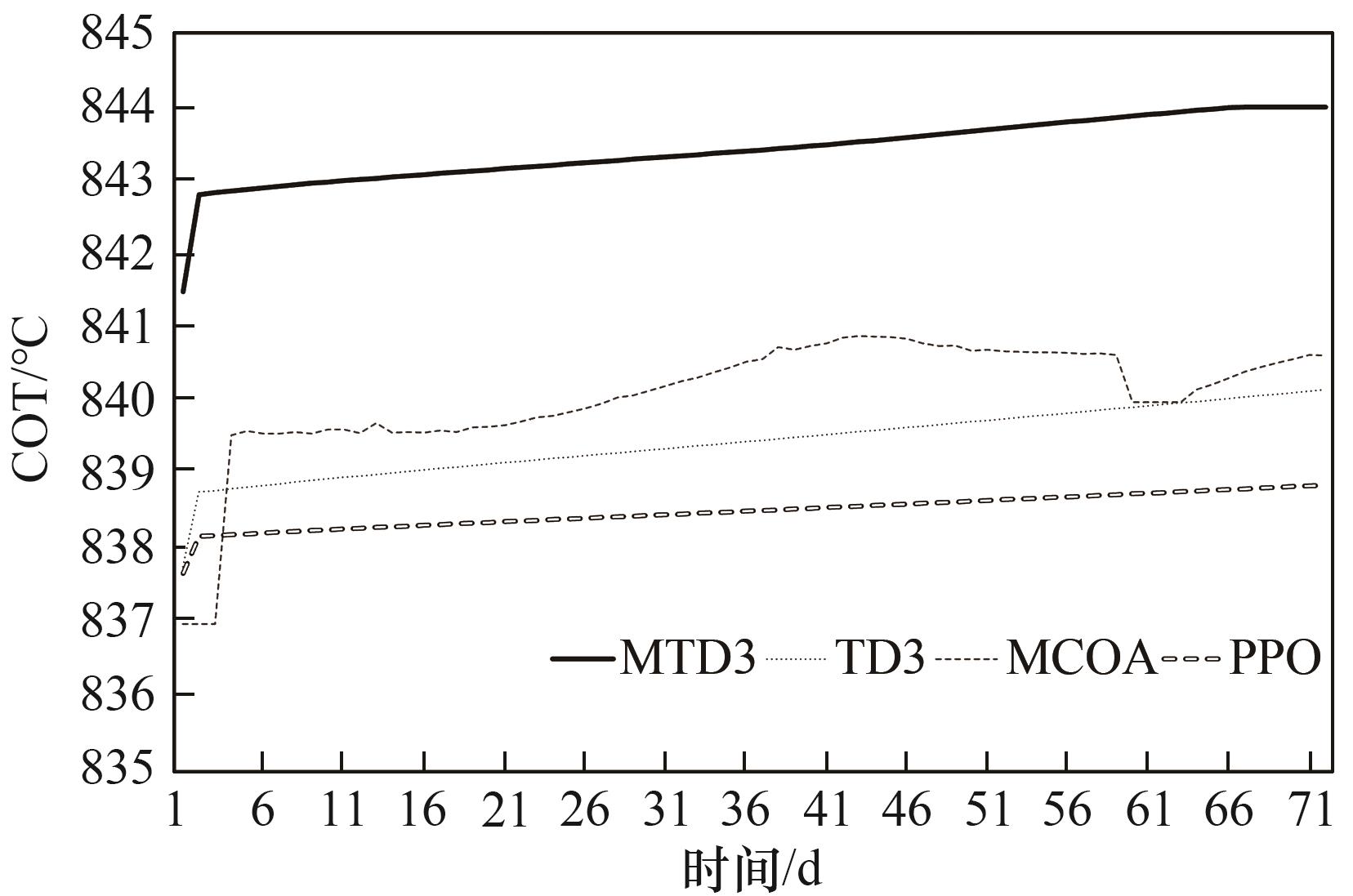

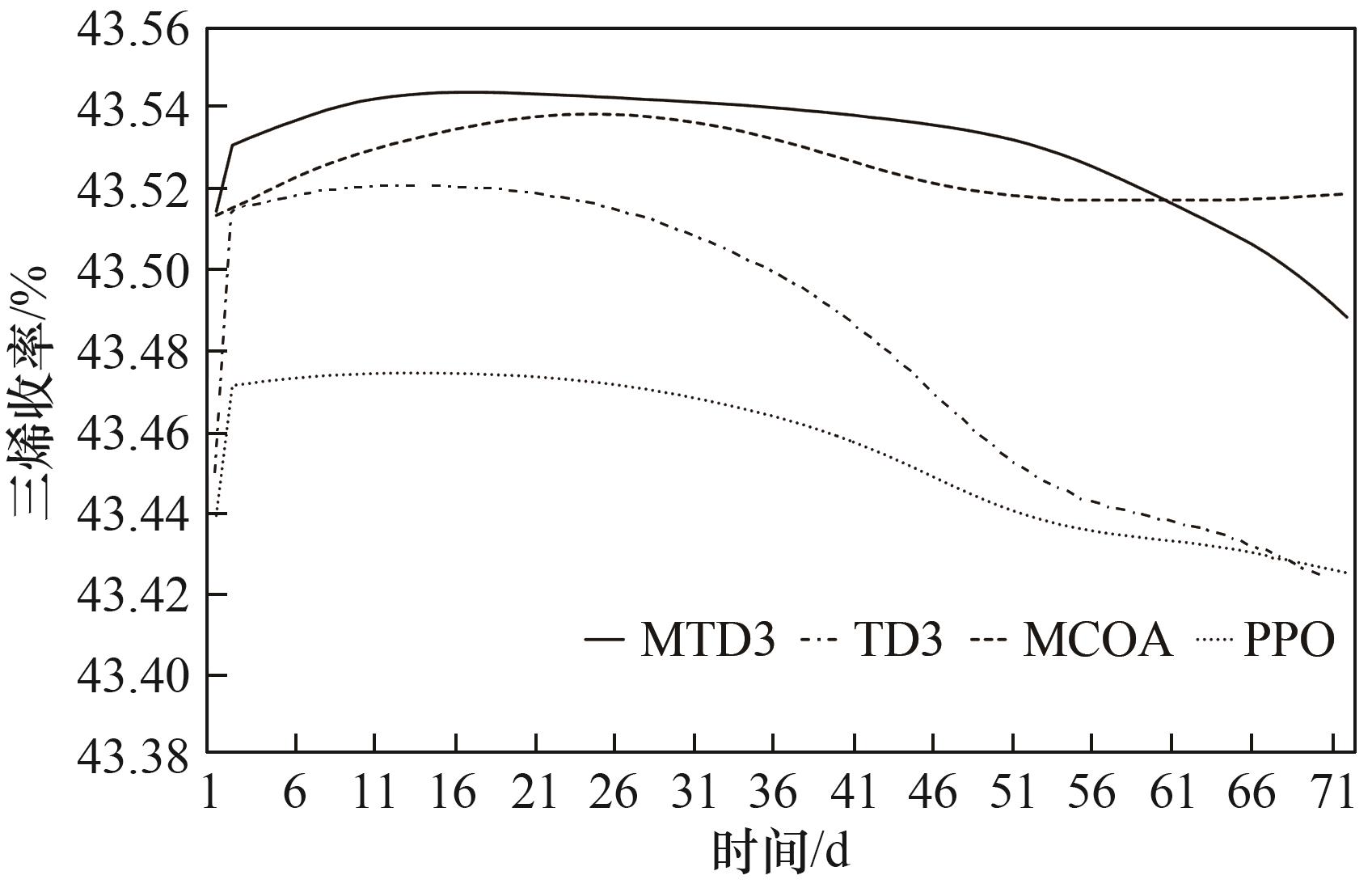
 分析
分析