• •
刘秀玥1( ), 张佳鑫2, 宋朝阳1, 董立春1()
), 张佳鑫2, 宋朝阳1, 董立春1()
收稿日期:2025-11-25
修回日期:2025-12-28
出版日期:2026-01-04
通讯作者:
董立春
作者简介:刘秀玥 (2001—),女,硕士研究生,202418021066@stu.cqu.edu.cn
基金资助:
Xiuyue LIU1(), Jiaxin ZHANG2, Chaoyang SONG1, Lichun DONG1()
Received:2025-11-25
Revised:2025-12-28
Online:2026-01-04
Contact:
Lichun DONG
摘要:
深度学习模型在化工故障诊断中具备较好的特征提取能力,但在非线性高维工况下,单一网络难以同时捕捉长短期时序依赖,易产生信息缺失与特征冗余。本文提出双阶段双通道多头自注意力故障分类模型。第一阶段采用GRU–LSTM双通道并行提取互补时序表征:LSTM捕获长期时序依赖特征,GRU捕获短期时序依赖特征;并通过多头自注意力完成融合与赋权,突出关键特征并抑制冗余。随后依据故障混淆值将故障划分为E类与H类,H类故障进入第二阶段,利用动态核PCA计算T²与SPE统计值并构建增强特征矩阵,提升模型对微弱偏移、渐变退化与传播型异常的灵敏度。田纳西–伊斯曼过程实验表明,该模型在检测与诊断精度、鲁棒性与泛化性方面优于明显对比方法。
中图分类号:
刘秀玥, 张佳鑫, 宋朝阳, 董立春. 基于双阶段双通道深度学习的化工故障分类模型[J]. 化工学报, DOI: 10.11949/0438-1157.20251320.
Xiuyue LIU, Jiaxin ZHANG, Chaoyang SONG, Lichun DONG. A two-stage dual-channel deep learning model for chemical fault classification[J]. CIESC Journal, DOI: 10.11949/0438-1157.20251320.
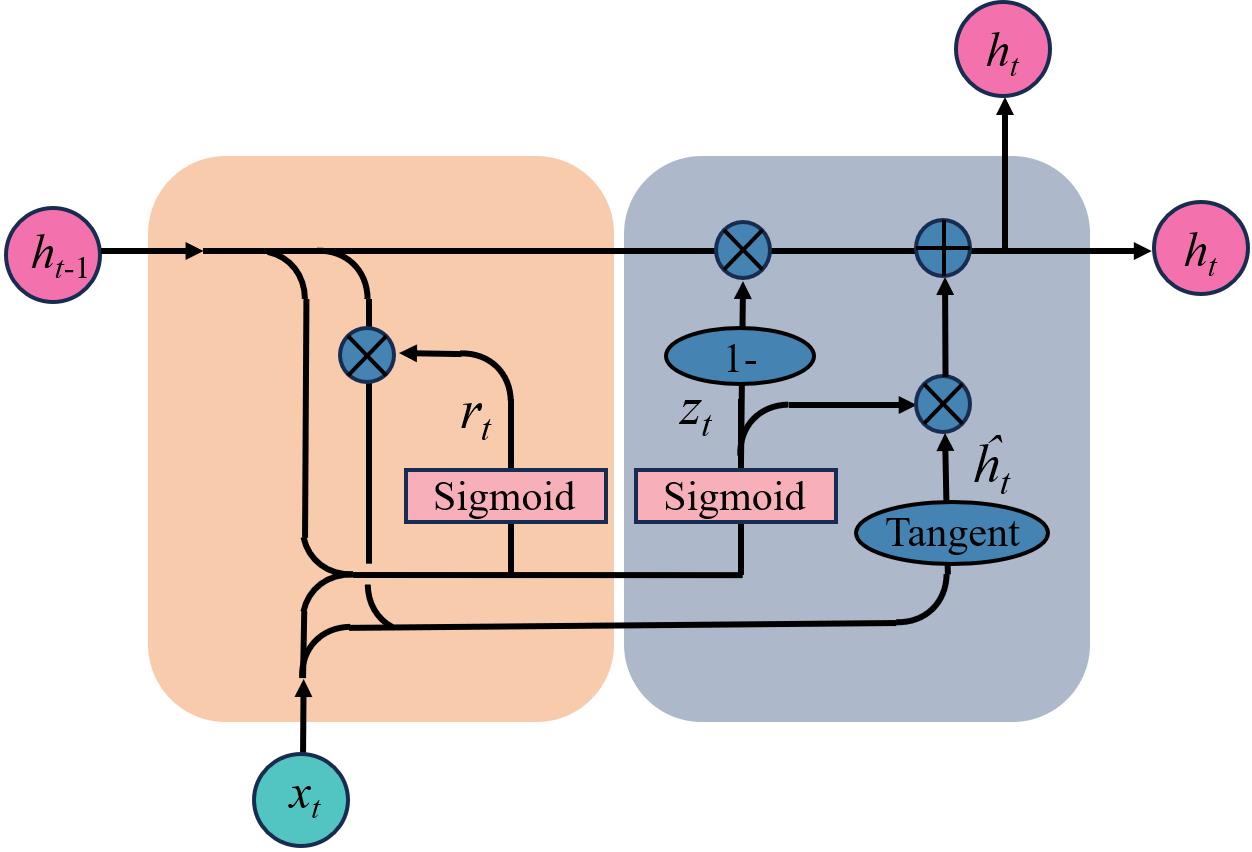
图1 GRU网络结构图
Fig. 1 Schematic network structure of GRU
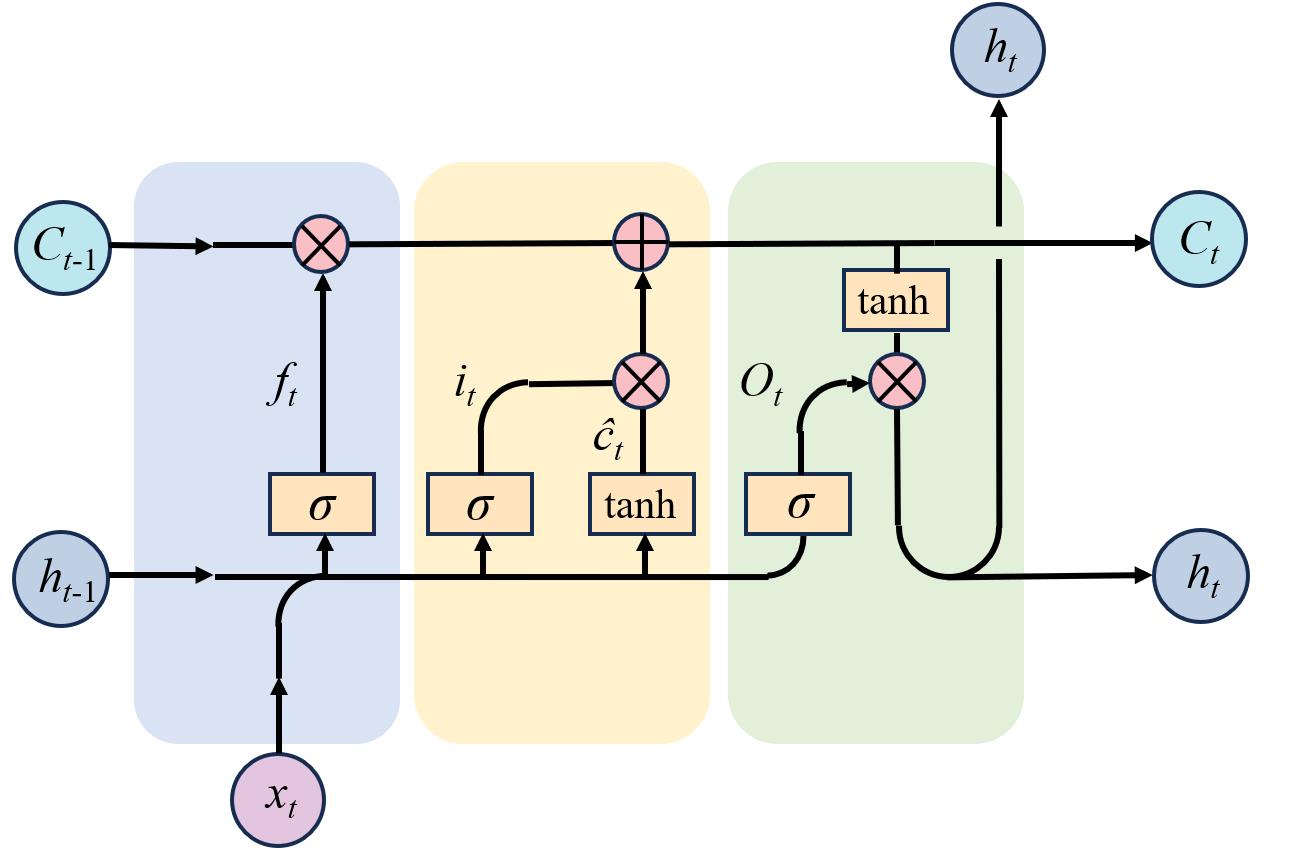
图2 LSTM网络结构示意图
Fig. 2 Schematic network structure of LSTM
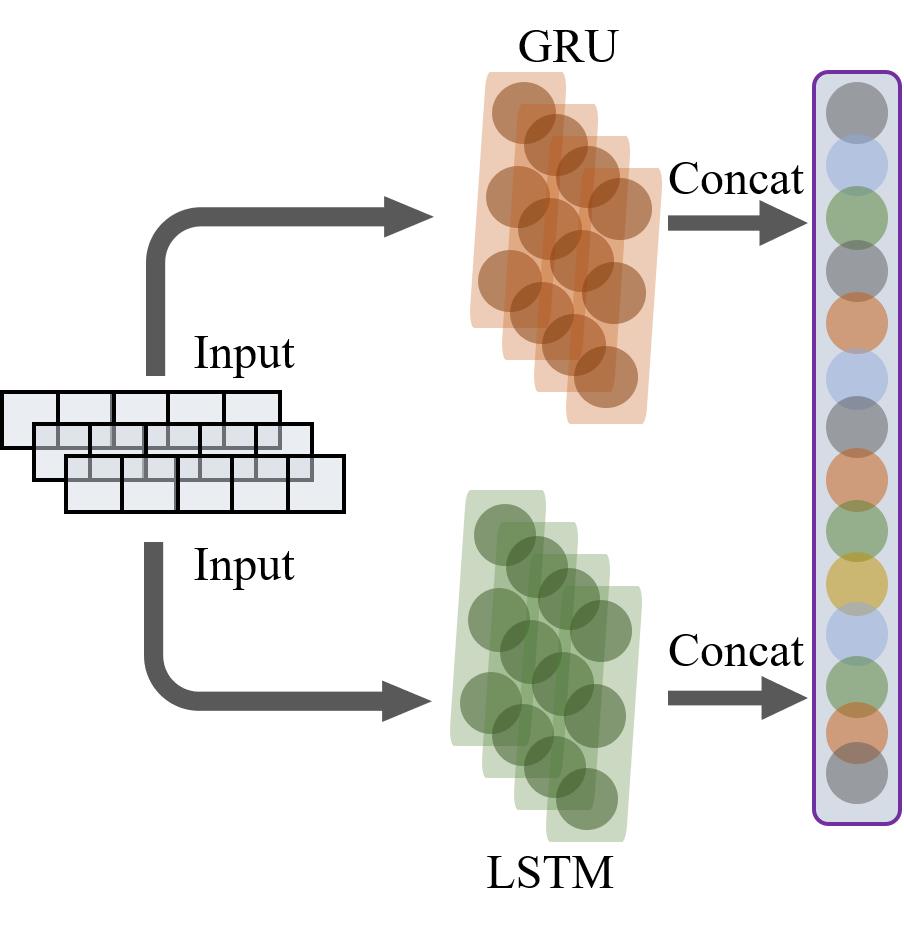
图3 由GRU 与 LSTM组成的并行双通道网络结构
Fig. 3 A parallel two-channel network incorporating both GRU and LSTM
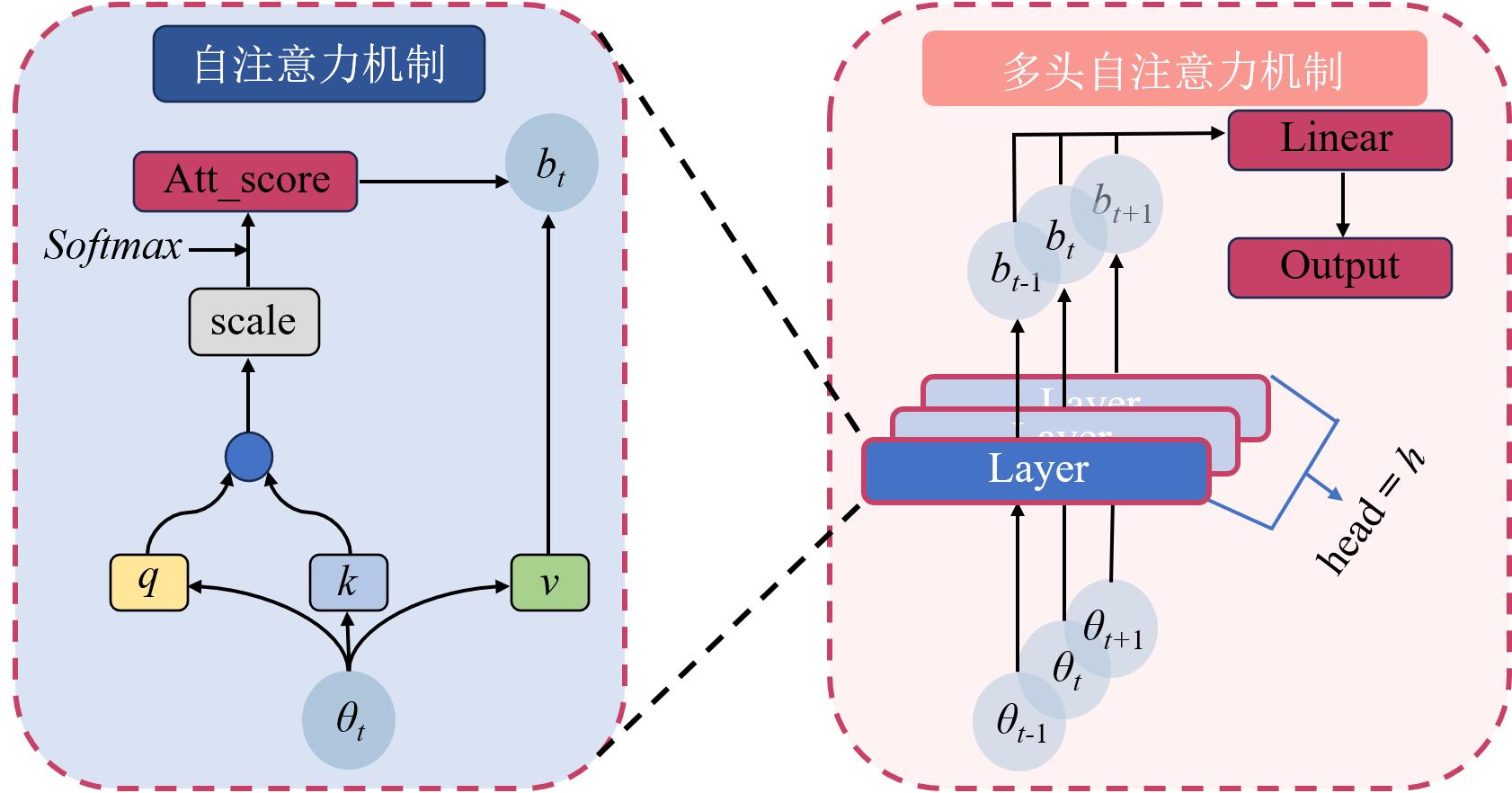
图4 多头自注意力机制结构示意图
Fig. 4 The schematic architecture of the MHSA
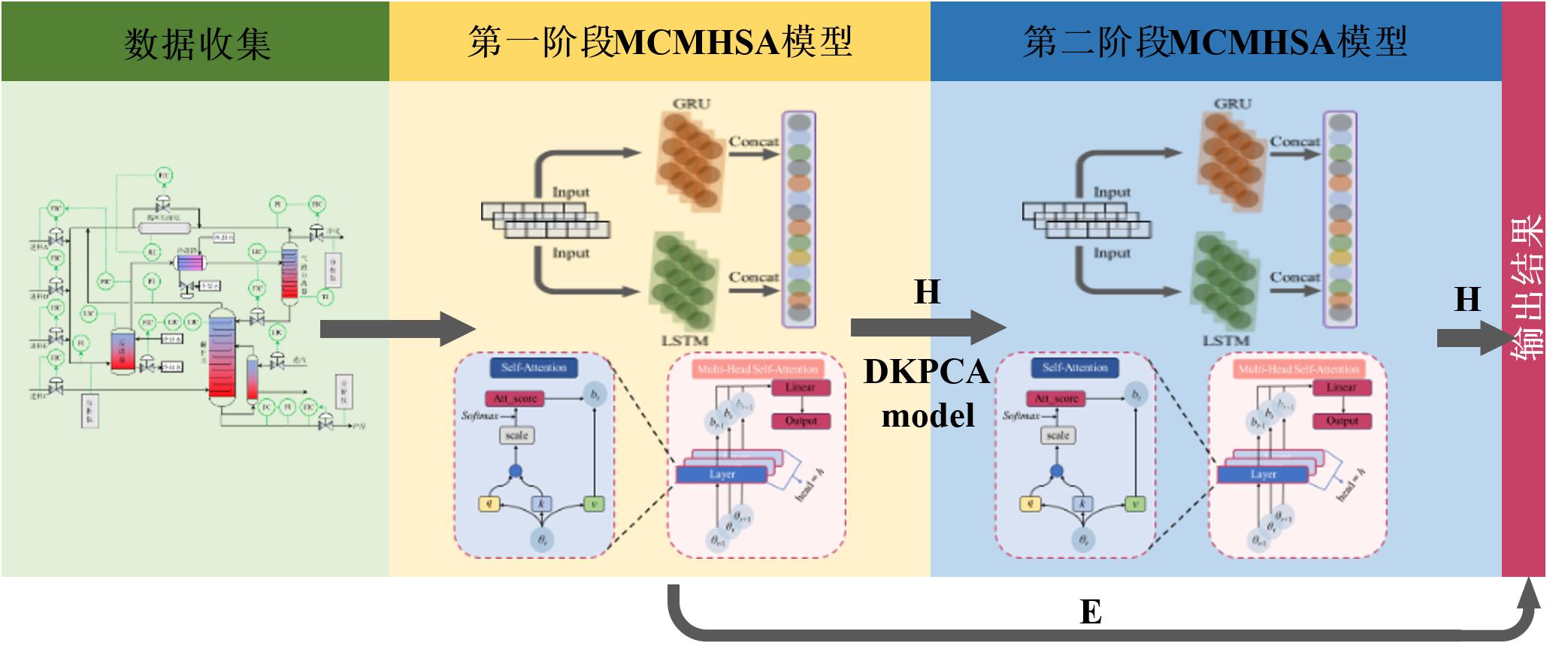
图5 双级故障诊断模型步骤
Fig. 5 The fault diagnosis process of the Bi-MCMHSA model
| 项目 | 预测 | ||
|---|---|---|---|
| 阳性 (P) | 阴性 (N) | ||
| 实际 | 真 (T) | TP | TN |
| 假 (F) | FP | FN | |
表1 混淆矩阵
Table 1 Confusion matrix
| 项目 | 预测 | ||
|---|---|---|---|
| 阳性 (P) | 阴性 (N) | ||
| 实际 | 真 (T) | TP | TN |
| 假 (F) | FP | FN | |
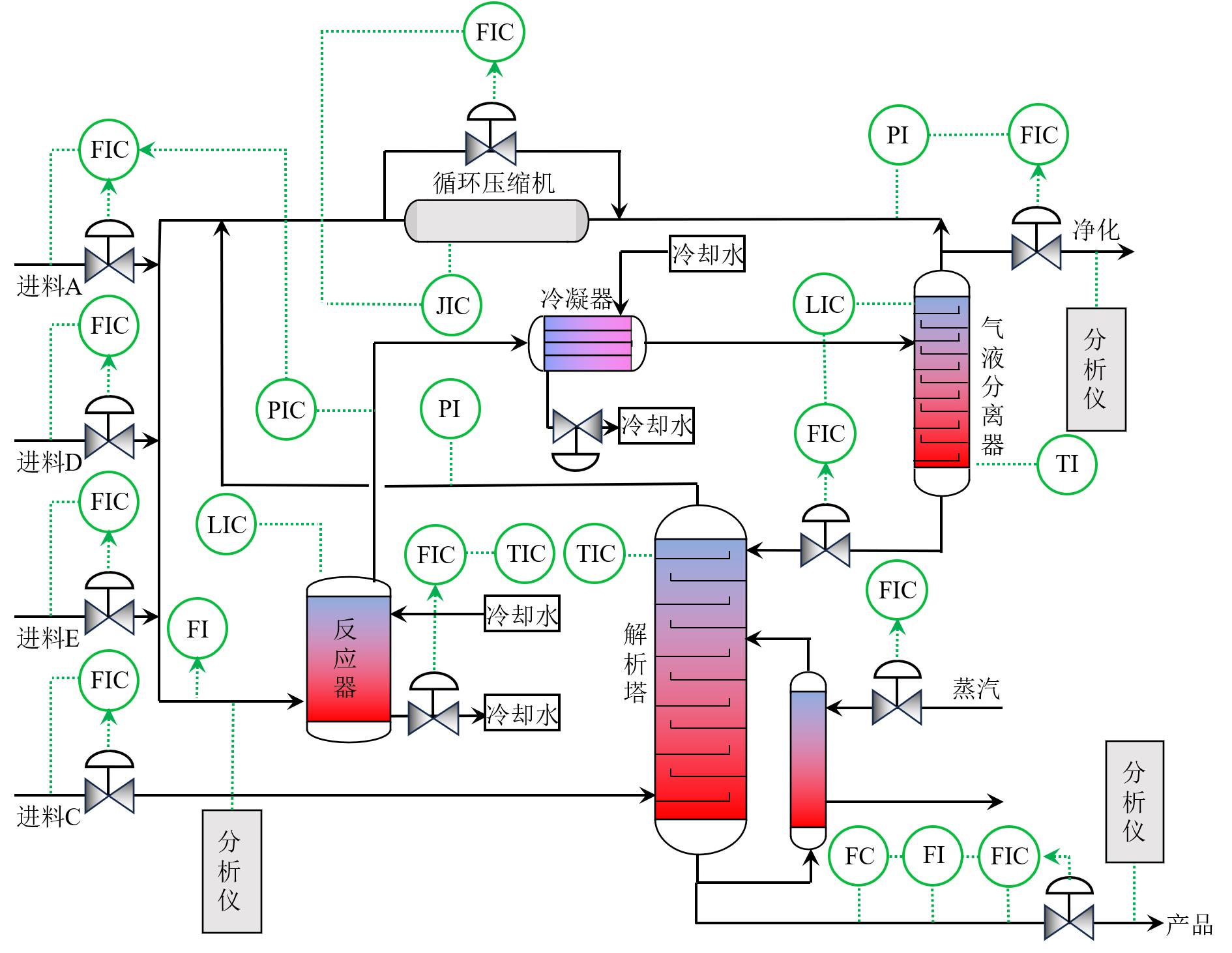
图6 田纳西-伊斯曼过程流程图
Fig. 6 Flow chart of the TE process
| 编号 | 描述 | 故障类型 |
|---|---|---|
| 1 | A/C进料流量比变化 | 阶跃 |
| 2 | 组分B含量变化 | 阶跃 |
| 3 | 物料D的温度变化 | 阶跃 |
| 4 | 反应器冷却水入口温度变化 | 阶跃 |
| 5 | 冷凝器冷却水入口温度变化 | 阶跃 |
| 6 | 物料A损失 | 阶跃 |
| 7 | 物料C压力损失 | 阶跃 |
| 8 | 物料A,B和C组分变化 | 随机变量 |
| 9 | 物料D的温度发生变化 | 随机变量 |
| 10 | 物料C的温度发生变化 | 随机变量 |
| 11 | 反应器冷却水入口温度变化 | 随机变量 |
| 12 | 冷凝器冷却水入口温度变化 | 随机变量 |
| 13 | 反应动力学特性发生变化 | 缓慢漂移 |
| 14 | 反应器冷却水阀门 | 粘滞 |
| 15 | 冷凝器冷却水阀门粘滞 | 粘滞 |
| 16-20 | 未知 | 未知 |
表2 TE过程故障说明
Table 2 Faults in the TE process
| 编号 | 描述 | 故障类型 |
|---|---|---|
| 1 | A/C进料流量比变化 | 阶跃 |
| 2 | 组分B含量变化 | 阶跃 |
| 3 | 物料D的温度变化 | 阶跃 |
| 4 | 反应器冷却水入口温度变化 | 阶跃 |
| 5 | 冷凝器冷却水入口温度变化 | 阶跃 |
| 6 | 物料A损失 | 阶跃 |
| 7 | 物料C压力损失 | 阶跃 |
| 8 | 物料A,B和C组分变化 | 随机变量 |
| 9 | 物料D的温度发生变化 | 随机变量 |
| 10 | 物料C的温度发生变化 | 随机变量 |
| 11 | 反应器冷却水入口温度变化 | 随机变量 |
| 12 | 冷凝器冷却水入口温度变化 | 随机变量 |
| 13 | 反应动力学特性发生变化 | 缓慢漂移 |
| 14 | 反应器冷却水阀门 | 粘滞 |
| 15 | 冷凝器冷却水阀门粘滞 | 粘滞 |
| 16-20 | 未知 | 未知 |
| 模型 | LSTM | GRU | MHSA |
|---|---|---|---|
| LSTM | 32 | / | / |
| GRU | / | 64 | / |
| MC | 32 | 64 | / |
| MCMHSA | 32 | 64 | 6/36 |
| Bi-MCMHSA | 32 | 64 | 4/24 |
表 3 各个同源模型网络参数表
Table 3 Network parameter for each homologous model
| 模型 | LSTM | GRU | MHSA |
|---|---|---|---|
| LSTM | 32 | / | / |
| GRU | / | 64 | / |
| MC | 32 | 64 | / |
| MCMHSA | 32 | 64 | 6/36 |
| Bi-MCMHSA | 32 | 64 | 4/24 |
| 模型 | 参数数量 (个) | 训练时间 (秒) | 测试时间 (秒) |
|---|---|---|---|
| LSTM | 11500 | 370 | 1.81 |
| GRU | 8800 | 259 | 2.61 |
| MC | 41000 | 1032 | 4.13 |
| MCMHSA | 55000 | 1056 | 4.20 |
| Bi-MCMHSA | 109000 | 1341 | 6.01 |
表 4 各个模型训练和测试时间及可学习参数表
Table 4 Training and testing time and learnable parameters table for each model
| 模型 | 参数数量 (个) | 训练时间 (秒) | 测试时间 (秒) |
|---|---|---|---|
| LSTM | 11500 | 370 | 1.81 |
| GRU | 8800 | 259 | 2.61 |
| MC | 41000 | 1032 | 4.13 |
| MCMHSA | 55000 | 1056 | 4.20 |
| Bi-MCMHSA | 109000 | 1341 | 6.01 |
| 故障 | LSTM | GRU | MC | MCMHSA | Bi-MCMHSA |
|---|---|---|---|---|---|
| 01 | 98.81 | 98.06 | 99.13 | 99.75 | 99.75 |
| 02 | 98.44 | 98.44 | 98.63 | 99.63 | 99.63 |
| 03 | 13.38 | 22.44 | 25.19 | 78.13 | 71.56 |
| 04 | 99.56 | 97.31 | 97.75 | 98.63 | 98.63 |
| 05 | 97.94 | 98.38 | 99.13 | 99.81 | 99.81 |
| 06 | 99.94 | 100 | 100 | 100 | 100 |
| 07 | 99.94 | 99.88 | 100 | 99.94 | 99.94 |
| 08 | 84.13 | 80.25 | 89.81 | 88.06 | 96.38 |
| 09 | 0.44 | 0.21 | 1.06 | 22.94 | 30.56 |
| 10 | 67.31 | 53.19 | 90.06 | 92.31 | 92.31 |
| 11 | 70.94 | 77.44 | 83.88 | 92.38 | 92.38 |
| 12 | 84.81 | 81.69 | 93.06 | 96.31 | 96.31 |
| 13 | 90.69 | 89.38 | 93.88 | 95.44 | 95.44 |
| 14 | 95.06 | 95.44 | 97.31 | 98.44 | 98.44 |
| 15 | 0.69 | 0.69 | 10.50 | 35.69 | 63.56 |
| 16 | 38.50 | 67.81 | 88.69 | 90.25 | 93.56 |
| 17 | 93.38 | 92.06 | 93.50 | 94.31 | 94.31 |
| 18 | 86.38 | 87.56 | 90.88 | 92.25 | 92.25 |
| 19 | 62.19 | 83.06 | 94.50 | 86.94 | 92.81 |
| 20 | 76.00 | 82.56 | 94.69 | 95.13 | 95.13 |
| 平均 | 72.93 | 75.28 | 82.08 | 87.82 | 90.19 |
表5 不同故障诊断模型的FDR (%)
Table 5 FDR (%) of different fault diagnosis models
| 故障 | LSTM | GRU | MC | MCMHSA | Bi-MCMHSA |
|---|---|---|---|---|---|
| 01 | 98.81 | 98.06 | 99.13 | 99.75 | 99.75 |
| 02 | 98.44 | 98.44 | 98.63 | 99.63 | 99.63 |
| 03 | 13.38 | 22.44 | 25.19 | 78.13 | 71.56 |
| 04 | 99.56 | 97.31 | 97.75 | 98.63 | 98.63 |
| 05 | 97.94 | 98.38 | 99.13 | 99.81 | 99.81 |
| 06 | 99.94 | 100 | 100 | 100 | 100 |
| 07 | 99.94 | 99.88 | 100 | 99.94 | 99.94 |
| 08 | 84.13 | 80.25 | 89.81 | 88.06 | 96.38 |
| 09 | 0.44 | 0.21 | 1.06 | 22.94 | 30.56 |
| 10 | 67.31 | 53.19 | 90.06 | 92.31 | 92.31 |
| 11 | 70.94 | 77.44 | 83.88 | 92.38 | 92.38 |
| 12 | 84.81 | 81.69 | 93.06 | 96.31 | 96.31 |
| 13 | 90.69 | 89.38 | 93.88 | 95.44 | 95.44 |
| 14 | 95.06 | 95.44 | 97.31 | 98.44 | 98.44 |
| 15 | 0.69 | 0.69 | 10.50 | 35.69 | 63.56 |
| 16 | 38.50 | 67.81 | 88.69 | 90.25 | 93.56 |
| 17 | 93.38 | 92.06 | 93.50 | 94.31 | 94.31 |
| 18 | 86.38 | 87.56 | 90.88 | 92.25 | 92.25 |
| 19 | 62.19 | 83.06 | 94.50 | 86.94 | 92.81 |
| 20 | 76.00 | 82.56 | 94.69 | 95.13 | 95.13 |
| 平均 | 72.93 | 75.28 | 82.08 | 87.82 | 90.19 |
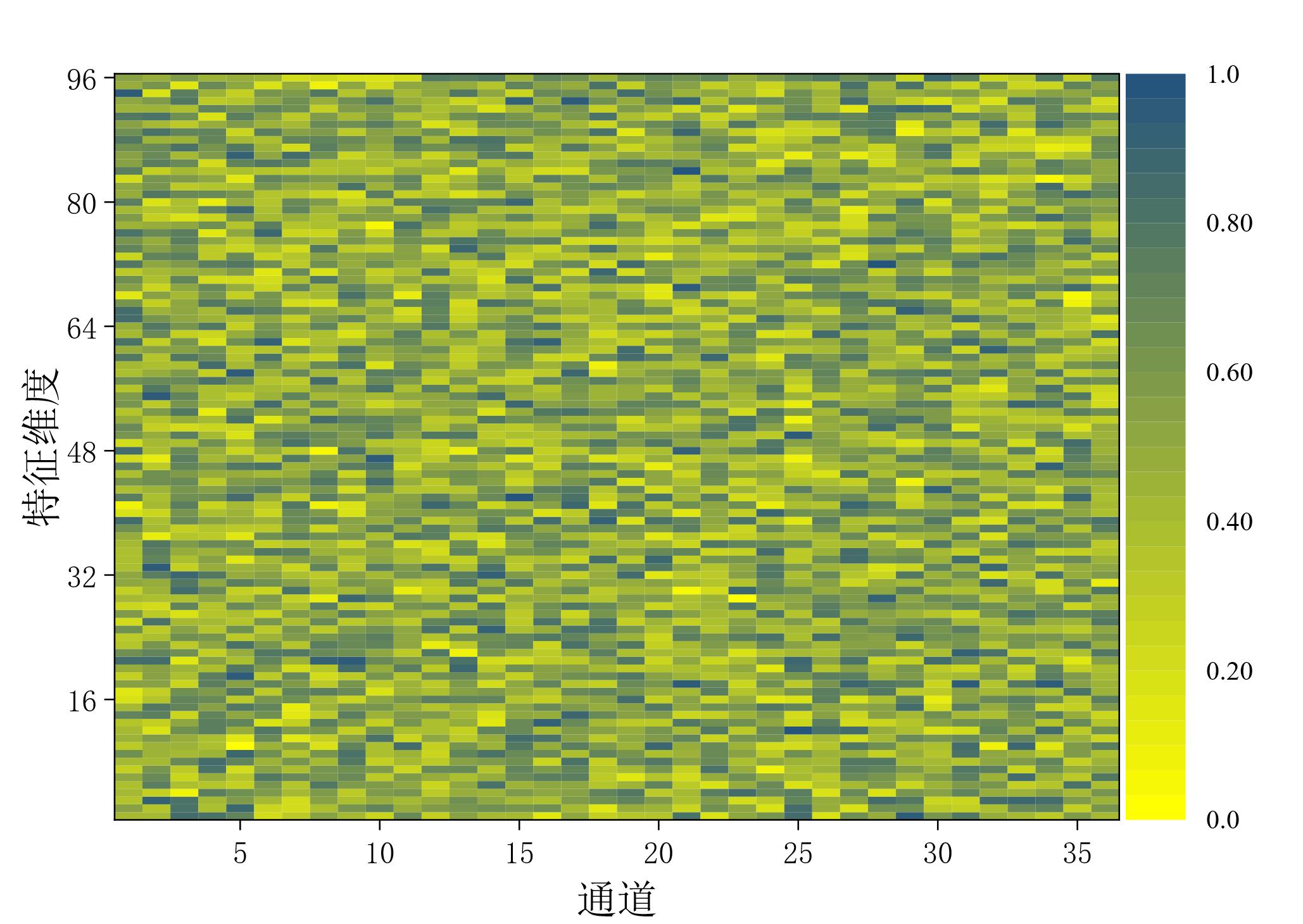
图 7 高阶特征 (LSTM) 和低阶特征 (GRU) 输出权重可视化
Fig. 7 Visualization of output weights for high-order features (LSTM) and low-order features (GRU)
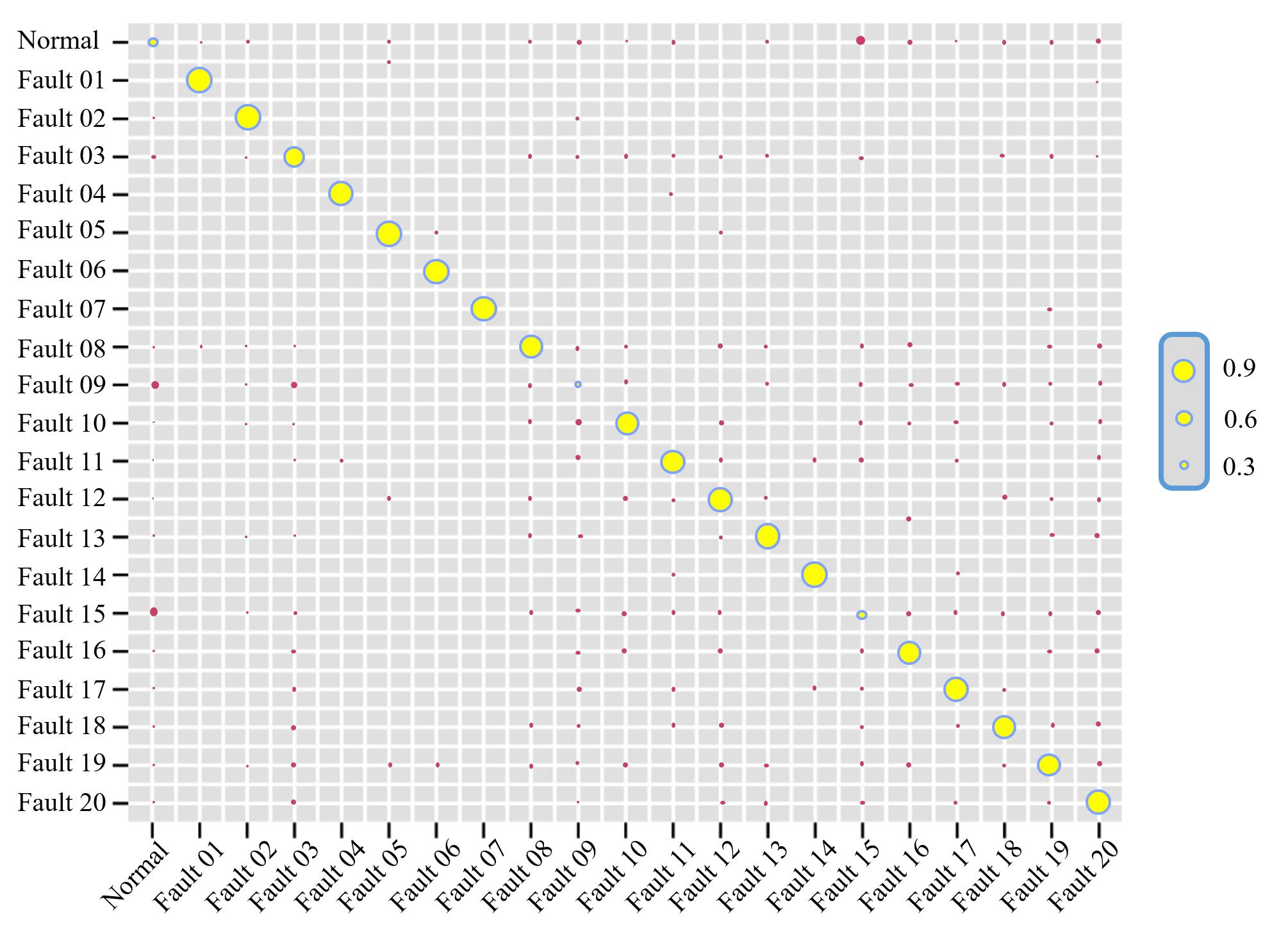
图8 MCMHSA模型的故障诊断结果混淆矩阵图
Fig. 8 The confusion matrix diagram of fault diagnosis results of MCMHSA model
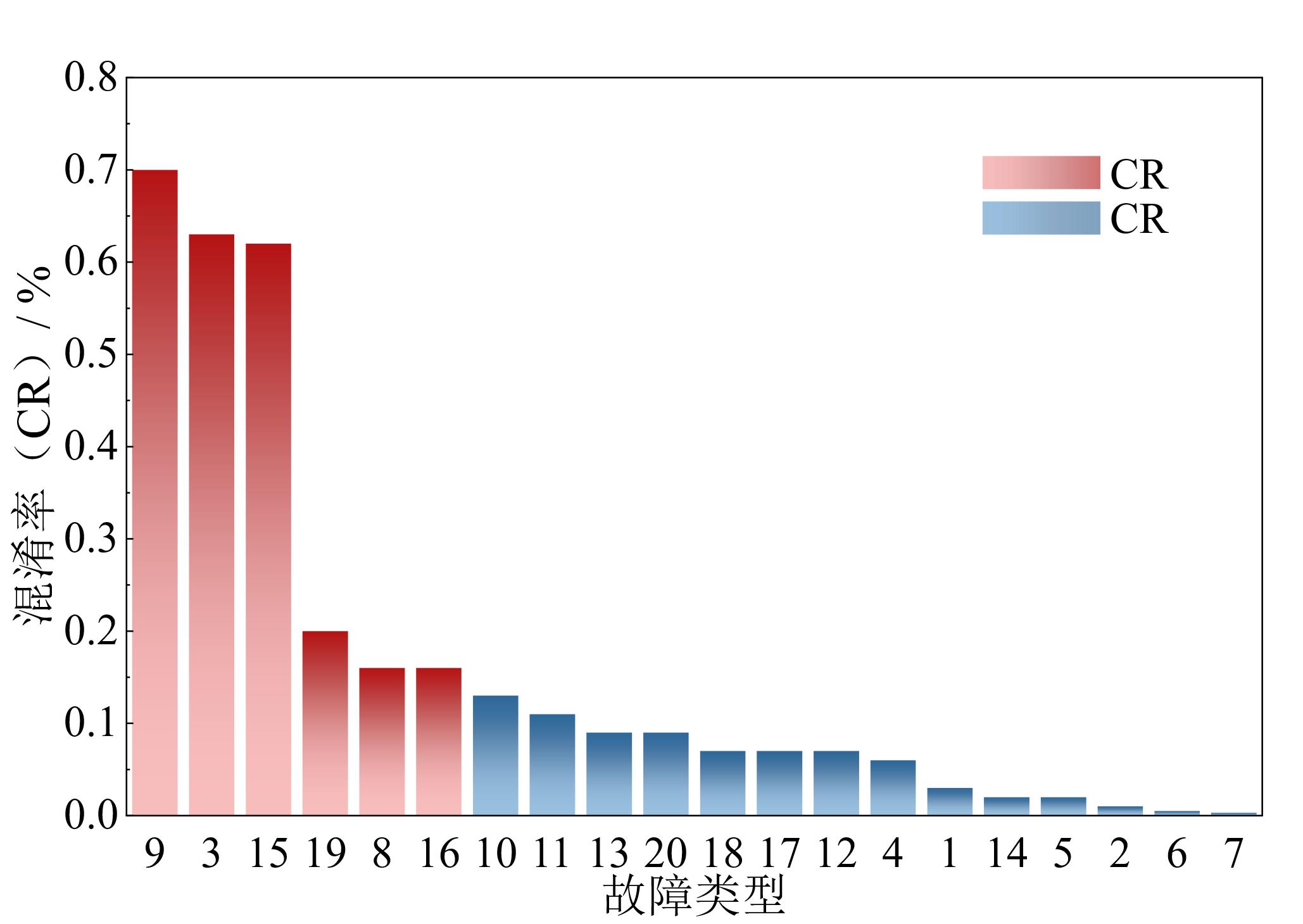
图9 20种故障类型的CR值
Fig. 9 The CR values of all 20 faults
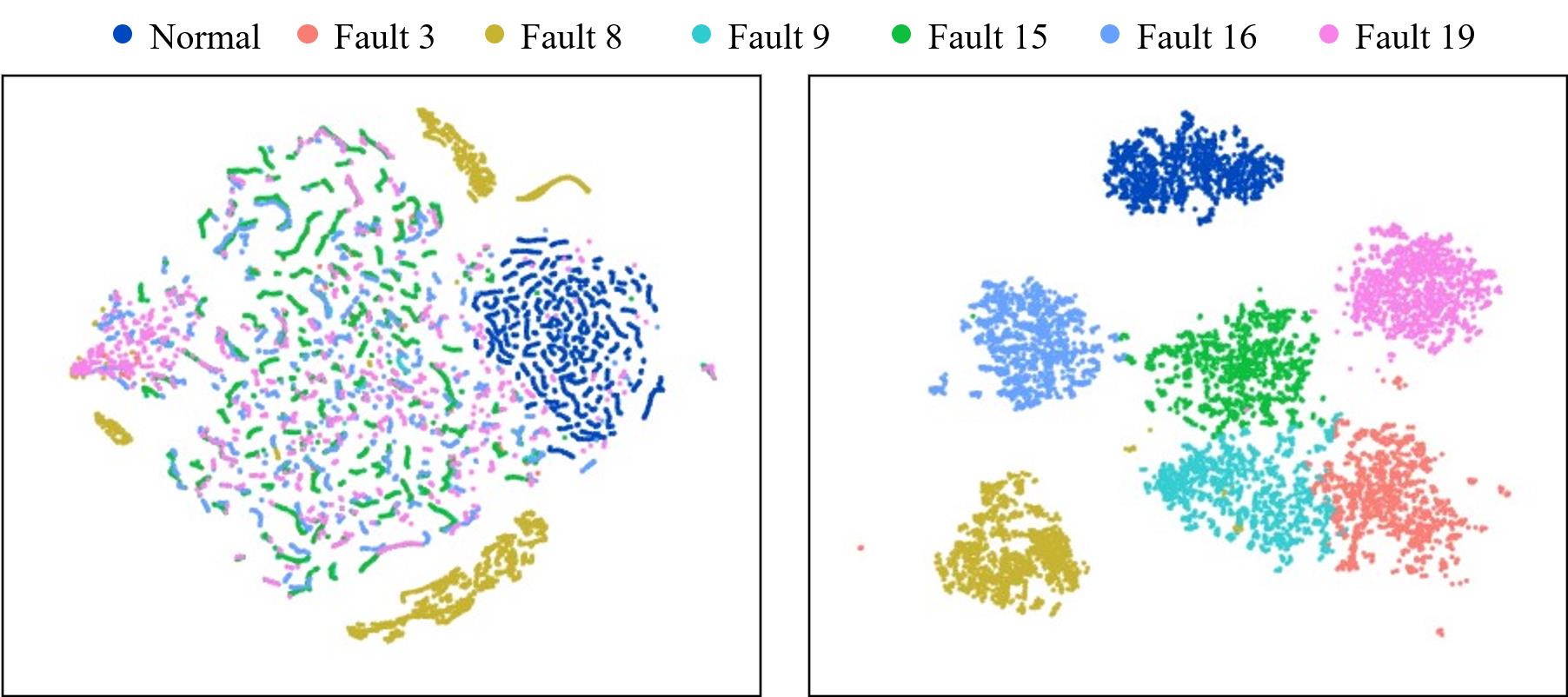
图10 t-SNE可视化特征分布
Fig. 10 t-SNE visualization of feature distributions
| 故障 | DPCA-DR[ | KPCA- KICA[ | KPLS-OPM[ | DCNN[ | GRU-EDCNN[ | SFIN[ | Bi-MCMHSA |
|---|---|---|---|---|---|---|---|
| 01 | 99.60 | 100.00 | 98.55 | 97.80 | 98.43 | 100.00 | 99.75 |
| 02 | 98.50 | 99.00 | 75.57 | 98.60 | 98.13 | 100.00 | 99.63 |
| 03 | 2.10 | 8.00 | 76.36 | 98.50 | 92.25 | 97.51 | 71.56 |
| 04 | 99.80 | 100.00 | 63.23 | 91.70 | 95.51 | 100.00 | 98.63 |
| 05 | 99.90 | 30.00 | 99.05 | 97.60 | 92.11 | 96.12 | 99.81 |
| 06 | 99.90 | 100.00 | 90.27 | 91.50 | 98.14 | 100.00 | 100 |
| 07 | 99.90 | 100.00 | 94.13 | 97.50 | 98.56 | 100.00 | 99.94 |
| 08 | 98.50 | 98.00 | 96.70 | 99.90 | 95.67 | 95.57 | 96.38 |
| 09 | 2.00 | 6.00 | 85.14 | 92.20 | 50.16 | 93.63 | 30.56 |
| 10 | 95.60 | 77.00 | 87.99 | 58.40 | 97.25 | 99.45 | 92.31 |
| 11 | 96.50 | 78.00 | 81.78 | 96.40 | 98.1 | 100.00 | 92.38 |
| 12 | 99.80 | 98.00 | 72.00 | 95.60 | 98.85 | 99.31 | 96.31 |
| 13 | 95.80 | 97.00 | 87.21 | 95.70 | 97.45 | 97.92 | 95.44 |
| 14 | 99.80 | 100.00 | 83.85 | 98.70 | 99.12 | 100.00 | 98.44 |
| 15 | 38.50 | 6.00 | 80.50 | 28.00 | 51.63 | 77.15 | 63.56 |
| 16 | 97.60 | 74.00 | 68.36 | 44.20 | 47.19 | 44.60 | 93.56 |
| 17 | 97.60 | 95.00 | 81.78 | 94.50 | 97.65 | 100.00 | 94.31 |
| 18 | 90.50 | 90.00 | 89.28 | 93.90 | 95.15 | 100.00 | 92.25 |
| 19 | 97.10 | 70.00 | 89.78 | 98.60 | 96.45 | 100.00 | 92.81 |
| 20 | 90.80 | 69.00 | 95.70 | 93.30 | 96.11 | 99.72 | 95.13 |
| 平均 | 84.99 | 74.75 | 84.86 | 88.20 | 89.69 | 94.84 | 90.19 |
表6 不同FDD模型在TE过程中的FDR (%) 对比
Table 6 FDR (%) of different FDD models in the TE process
| 故障 | DPCA-DR[ | KPCA- KICA[ | KPLS-OPM[ | DCNN[ | GRU-EDCNN[ | SFIN[ | Bi-MCMHSA |
|---|---|---|---|---|---|---|---|
| 01 | 99.60 | 100.00 | 98.55 | 97.80 | 98.43 | 100.00 | 99.75 |
| 02 | 98.50 | 99.00 | 75.57 | 98.60 | 98.13 | 100.00 | 99.63 |
| 03 | 2.10 | 8.00 | 76.36 | 98.50 | 92.25 | 97.51 | 71.56 |
| 04 | 99.80 | 100.00 | 63.23 | 91.70 | 95.51 | 100.00 | 98.63 |
| 05 | 99.90 | 30.00 | 99.05 | 97.60 | 92.11 | 96.12 | 99.81 |
| 06 | 99.90 | 100.00 | 90.27 | 91.50 | 98.14 | 100.00 | 100 |
| 07 | 99.90 | 100.00 | 94.13 | 97.50 | 98.56 | 100.00 | 99.94 |
| 08 | 98.50 | 98.00 | 96.70 | 99.90 | 95.67 | 95.57 | 96.38 |
| 09 | 2.00 | 6.00 | 85.14 | 92.20 | 50.16 | 93.63 | 30.56 |
| 10 | 95.60 | 77.00 | 87.99 | 58.40 | 97.25 | 99.45 | 92.31 |
| 11 | 96.50 | 78.00 | 81.78 | 96.40 | 98.1 | 100.00 | 92.38 |
| 12 | 99.80 | 98.00 | 72.00 | 95.60 | 98.85 | 99.31 | 96.31 |
| 13 | 95.80 | 97.00 | 87.21 | 95.70 | 97.45 | 97.92 | 95.44 |
| 14 | 99.80 | 100.00 | 83.85 | 98.70 | 99.12 | 100.00 | 98.44 |
| 15 | 38.50 | 6.00 | 80.50 | 28.00 | 51.63 | 77.15 | 63.56 |
| 16 | 97.60 | 74.00 | 68.36 | 44.20 | 47.19 | 44.60 | 93.56 |
| 17 | 97.60 | 95.00 | 81.78 | 94.50 | 97.65 | 100.00 | 94.31 |
| 18 | 90.50 | 90.00 | 89.28 | 93.90 | 95.15 | 100.00 | 92.25 |
| 19 | 97.10 | 70.00 | 89.78 | 98.60 | 96.45 | 100.00 | 92.81 |
| 20 | 90.80 | 69.00 | 95.70 | 93.30 | 96.11 | 99.72 | 95.13 |
| 平均 | 84.99 | 74.75 | 84.86 | 88.20 | 89.69 | 94.84 | 90.19 |
| [1] | 宋冰, 郭涛, 侍洪波, 等. 基于双子空间并行回归的化工过程质量相关故障检测方法[J]. 化工学报, 2023, 74(11): 4600-4610. |
| Song B, Guo T, Shi H B, et al. A chemical process quality-related fault detection method based on twin-space parallel regression [J]. CIESC Journal, 2023, 74(11): 4600-4610. | |
| [2] | 华宇辉, 胡文军, 崔胜男, 等. 基于特征重要性的质量相关故障诊断与量化评估[J]. 测控技术, 2025, 44(4): 25-34, 41. |
| Hua Y H, Hu W J, Cui S N, et al. Quality-related fault diagnosis and quantitative evaluation based on feature importance[J]. Measurement Control Technology, 2025, 44(4): 25-34, 41. | |
| [3] | 江升, 旷天亮, 李秀喜. 基于稀疏过滤特征学习的化工过程故障检测方法[J]. 化工学报, 2019, 70(12): 4698-4709. |
| Jiang S, Kuang T L, Li X X. A chemical process fault detection method based on sparse filtering feature learning [J]. CIESC Journal, 2019, 70(12): 4698-4709. | |
| [4] | Chen H, Li J M, Wang X B, et al. Review of intelligent fault diagnosis for rotating machinery under imperfect data conditions[J]. Expert Systems with Applications, 2025, 285: 127726. |
| [5] | 张佳鑫, 张淼, 戴一阳, 等. 面向实际化工过程故障诊断的强化深度卷积神经网络模型构建与应用[J]. 化工进展, 2024, 43(9): 4833-4844. |
| Zhang J X, Zhang M, Dai Y Y, et al. Design and application of enhanced deep convolutional neural networks model for fault diagnosis in practical chemical processes[J]. Chemical Industry and Engineering Progress, 2024, 43(9): 4833-4844. | |
| [6] | Han S B, Yang L N, Duan D W, et al. A novel fault detection and identification method for complex chemical processes based on OSCAE and CNN[J]. Process Safety and Environmental Protection, 2024, 190: 322-334. |
| [7] | Ge Z Q, Song Z H, Ding S X, et al. Data mining and analytics in the process industry: the role of machine learning[J]. IEEE Access, 2017, 5: 20590-20616. |
| [8] | 谭开军, 申卫星. 数据驱动的化工过程异常工况自动识别与分析研究[J]. 化学工程与装备, 2025, (5):129-131. |
| Tan K J, Shen W X. Data-driven automatic identification and analysis of abnormal conditions in chemical processes[J]. Chemical Engineering Equipment, 2025, (5):129-131. | |
| [9] | Amin M T, Khan F, Ahmed S, et al. A data-driven Bayesian network learning method for process fault diagnosis[J]. Process Safety and Environmental Protection, 2021, 150: 110-122. |
| [10] | 钱强, 马萍, 王妮妮, 等. 样本不平衡下基于图卷积网络的化工过程故障诊断[J]. 哈尔滨工业大学学报, 2025, 57(9): 76-86. |
| Qian Q, Ma P, Wang N N, et al. Graph convolutional network-based fault diagnosis of chemical process under sample imbalance[J]. Journal of Harbin Institute of Technology, 2025, 57(9): 76-86. | |
| [11] | Men J K, Chen G H, Reniers G, et al. A hybrid deep belief network-based label distribution learning system for seismic damage estimation of liquid storage tanks[J]. Process Safety and Environmental Protection, 2023, 172: 908-922. |
| [12] | Ren X M, Gu H X, Wei W T. Tree-RNN: Tree structural recurrent neural network for network traffic classification[J]. Expert Systems with Applications, 2021, 167: 114363. |
| [13] | 周旭, 曹立文. 基于归一化的STFT-2D-CNN汽轮机轴承故障诊断方法[J]. 防爆电机, 2025, 60(5): 67-73. |
| Zhou X, Cao L W. STFT-2D-CNN fault diagnosis method for turbine bearings based on normalization[J]. Explosion-Proof Electric Machine, 2025, 60(5): 67-73. | |
| [14] | Li G Q, Atoui M A, Li X S. Attention-based multiscale temporal fusion network for uncertain-mode fault diagnosis in multimode processes[J]. Process Safety and Environmental Protection, 2025, 201: 107554. |
| [15] | 孙一夫, 孙怀宇, 陈众, 等. 基于改进鲸鱼算法优化LSTM的化工过程故障诊断方法[J]. 现代电子技术, 2024, 47(24): 73-80. |
| Sun Y F, Sun H Y, Chen Z, et al. Method of chemical process fault diagnosis based on MAWOA-LSTM[J]. Modern Electronics Technique, 2024, 47(24): 73-80. | |
| [16] | Zhang S Y, Qiu T. Semi-supervised LSTM ladder autoencoder for chemical process fault diagnosis and localization[J]. Chemical Engineering Science, 2022, 251: 117467. |
| [17] | Wang Y L, Pan Z F, Yuan X F, et al. A novel deep learning based fault diagnosis approach for chemical process with extended deep belief network[J]. ISA Transactions, 2020, 96: 457-467. |
| [18] | Zhu Y Q, Zhang R D, Gao F R. Industrial process fault diagnosis using dilated convolutional stacking bidirectional gated recurrent unit with high and low-order feature fusion[J]. Chemical Engineering Science, 2025, 305: 121164. |
| [19] | Zhu Y Q, Zhang C, Zhang R D, et al. Design of model fusion learning method based on deep bidirectional GRU neural network in fault diagnosis of industrial processes[J]. Chemical Engineering Science, 2025, 302: 120884. |
| [20] | Hochreiter S, Schmidhuber J. Long short-term memory[J]. Neural Computation, 1997, 9(8): 1735-1780. |
| [21] | 李云峰, 蔡梓文, 赵云, 等. 改进时间序列网络的短期电力负荷预测方法[J]. 湖南大学学报(自然科学版), 2025, 52(10): 205-216. |
| Li Y F, Cai Z W, Zhao Y, et al. Improved short-term power load forecasting method for time series network[J]. Journal of Hunan University (Natural Sciences), 2025, 52(10): 205-216. | |
| [22] | Wang C T, Shi H B, Song B, et al. Hierarchical multihead self-attention for time-series-based fault diagnosis[J]. Chinese Journal of Chemical Engineering, 2024, 70: 104-117. |
| [23] | Chang Y H, Li F D, Chen J L, et al. Efficient temporal flow Transformer accompanied with multi-head probsparse self-attention mechanism for remaining useful life prognostics[J]. Reliability Engineering System Safety, 2022, 226: 108701. |
| [24] | Liu Y, Niu G Q, Zhou J, et al. Hybrid intelligent fault diagnosis model based on improved MPCA-V for sensors in a laboratory-scale wastewater treatment process[J]. Industrial Engineering Chemistry Research, 2022, 61(50): 18445-18456. |
| [25] | 庞智敏, 王亚君, 富斯源. 基于优化概率神经网络的化工过程故障诊断[J]. 化学工程, 2025, 53(3): 89-94. |
| Pang Z M, Wang Y J, Fu S Y. Chemical process fault diagnosis based on optimized PNN[J]. Chemical Engineering, 2025, 53(3): 89-94. | |
| [26] | Zheng S D, Zhao J S. A new unsupervised data mining method based on the stacked autoencoder for chemical process fault diagnosis[J]. Computers Chemical Engineering, 2020, 135: 106755. |
| [27] | Yin S, Ding S X, Haghani A, et al. A comparison study of basic data-driven fault diagnosis and process monitoring methods on the benchmark Tennessee Eastman process[J]. Journal of Process Control, 2012, 22(9): 1567-1581. |
| [28] | Lee J M, Qin S J, Lee I B. Fault detection and diagnosis based on modified independent component analysis[J]. AIChE Journal, 2006, 52(10): 3501-3514. |
| [29] | Rato T J, Reis M S. Fault detection in the Tennessee Eastman benchmark process using dynamic principal components analysis based on decorrelated residuals (DPCA-DR)[J]. Chemometrics and Intelligent Laboratory Systems, 2013, 125: 101-108. |
| [30] | Zhang Y W. Enhanced statistical analysis of nonlinear processes using KPCA, KICA and SVM[J]. Chemical Engineering Science, 2009, 64(5): 801-811. |
| [31] | Yi J, Huang D, He H B, et al. A novel framework for fault diagnosis using kernel partial least squares based on an optimal preference matrix[J]. IEEE Transactions on Industrial Electronics, 2017, 64(5): 4315-4324. |
| [32] | Wu H, Zhao J S. Deep convolutional neural network model based chemical process fault diagnosis[J]. Computers Chemical Engineering, 2018, 115: 185-197. |
| [33] | Zhang J X, Zhang M, Feng Z M, et al. Gated recurrent unit-enhanced deep convolutional neural network for real-time industrial process fault diagnosis[J]. Process Safety and Environmental Protection, 2023, 175: 129-149. |
| [34] | Guo L J, Zhang Z L, Kang J X, et al. An interpretable chemical process fault diagnosis model: Spatiotemporal feature integration network[J]. Chemical Engineering Science, 2026, 320: 122588. |
| [1] | 周光正, 钟子翰, 黄彦群, 王学重. 基于原位成像与图像分析技术的结晶过程智能监测[J]. 化工学报, 2025, 76(9): 4351-4368. |
| [2] | 付文峰, 王振雷, 王昕. 基于DVAE-WAFFN-GAN的不平衡样本的工业过程性能评估方法[J]. 化工学报, 2025, 76(2): 769-786. |
| [3] | 赵武灵, 满奕. 基于变分编码器的纳米纤维素分子结构预测模型框架研究[J]. 化工学报, 2024, 75(9): 3221-3230. |
| [4] | 文华强, 孙全虎, 申威峰. 基于分子碎片化学空间的智能分子定向生成框架[J]. 化工学报, 2024, 75(4): 1655-1667. |
| [5] | 张领先, 刘斌, 邓琳, 任宇航. 基于改进TSO优化Xception的PEMFC故障诊断[J]. 化工学报, 2024, 75(3): 945-955. |
| [6] | 李文华, 叶洪涛, 罗文广, 刘乙奇. 基于MHSA-LSTM的软测量建模及其在化工过程中的应用[J]. 化工学报, 2024, 75(12): 4654-4665. |
| [7] | 温凯杰, 郭力, 夏诏杰, 陈建华. 一种耦合CFD与深度学习的气固快速模拟方法[J]. 化工学报, 2023, 74(9): 3775-3785. |
| [8] | 明迁, 高逸, 胡剑, 李盛杰, 王金江. 热交换器泄漏故障虚拟感知方法研究[J]. 化工学报, 2023, 74(4): 1836-1846. |
| [9] | 籍帅航, 王金江, 蔡睿, 孙雪皓, 葛伟凤. 数字孪生驱动的热交换器降阶建模及智能感知方法研究[J]. 化工学报, 2023, 74(10): 4218-4228. |
| [10] | 高学金, 程琨, 韩华云, 高慧慧, 齐咏生. 基于中心损失的条件生成式对抗网络的冷水机组故障诊断[J]. 化工学报, 2022, 73(9): 3950-3962. |
| [11] | 杨静, 林振康, 汤君, 樊铖, 孙克宁. 电池系统的故障特征以及多故障的诊断与识别[J]. 化工学报, 2022, 73(8): 3394-3405. |
| [12] | 孙哲, 金华强, 李康, 顾江萍, 黄跃进, 沈希. 基于知识数据化表达的制冷空调系统故障诊断方法[J]. 化工学报, 2022, 73(7): 3131-3144. |
| [13] | 张成, 潘立志, 李元. 基于加权统计特征KICA的故障检测与诊断方法[J]. 化工学报, 2022, 73(2): 827-837. |
| [14] | 齐书平, 王文龙, 张磊, 都健. 基于深度学习的金属离子-有机配体配位稳定常数的预测[J]. 化工学报, 2022, 73(12): 5461-5468. |
| [15] | 张弛, 李浩, 胡海涛, 朱翀, 张玉莹, 南国鹏, 舒悦. 基于自动特征工程的飞行器轴承故障诊断[J]. 化工学报, 2021, 72(S1): 430-436. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备 11010102001995号
京公网安备 11010102001995号

