化工学报 ›› 2023, Vol. 74 ›› Issue (2): 630-641.DOI: 10.11949/0438-1157.20221060
陈家辉( ), 杨鑫泽, 陈顾中, 宋震(), 漆志文
), 杨鑫泽, 陈顾中, 宋震(), 漆志文
收稿日期:2022-07-27
修回日期:2022-09-22
出版日期:2023-02-05
发布日期:2023-03-21
通讯作者:
宋震
作者简介:陈家辉(1998—),男,硕士研究生,y30200121@mail.ecust.edu.cn
Jiahui CHEN(), Xinze YANG, Guzhong CHEN, Zhen SONG(), Zhiwen QI
Received:2022-07-27
Revised:2022-09-22
Online:2023-02-05
Published:2023-03-21
Contact:
Zhen SONG
摘要:
分子性质预测模型是针对特定应用需求筛选设计化学品的有力工具,然而诸多相关建模过程中的测试集划分、交叉验证、算法选择等关键环节普遍存在严谨性不足的问题,模型真实预测性能难以保证。以基团贡献法预测离子液体密度为例,探讨了分子性质预测模型建模过程中数据集划分和交叉验证的重要性,提出了自动基团划分方法并研究了数据集中基团涉及分子个数对预测精度的影响。通过对比五种回归算法(多重线性回归、岭回归、随机森林、支持向量机、神经网络),基于岭回归的基团贡献模型预测性能最佳,在由1078种离子液体、共计23034个数据点组成的数据集上得到的平均相对误差为1.88%。
中图分类号:
陈家辉, 杨鑫泽, 陈顾中, 宋震, 漆志文. 以离子液体密度为例的分子性质预测模型建模方法探讨[J]. 化工学报, 2023, 74(2): 630-641.
Jiahui CHEN, Xinze YANG, Guzhong CHEN, Zhen SONG, Zhiwen QI. A critical discussion on developing molecular property prediction models: density of ionic liquids as example[J]. CIESC Journal, 2023, 74(2): 630-641.
图1 本文基团划分方法示意图
Fig.1 Schematic diagram of the group fragmentation used in this work
| 阴离子 | ||||||
|---|---|---|---|---|---|---|
 |  |  |  |  | ||
 |  |  |  |  |  | |
 |  |
|  |  |  | |
 |  |  |
|
|
| |
 |  |  |  |  | ||
| 阳离子 | ||||||
|  |
|
|
|
| |
 |  |
|
|
|
| |
 |  |  |  |  |  | |
| 取代基 | ||||||
|  |  |
|  |
|  |
 |
|
|
|  |  | |
 |  |  | ||||
表1 本文数据库中离子液体含有的基团种类
Table 1 Summary of IL groups involved in the current database
| 阴离子 | ||||||
|---|---|---|---|---|---|---|
| | | | | ||
| | | | | | |
| |
| | | | |
| | |
|
|
| |
| | | | | ||
| 阳离子 | ||||||
| |
|
|
|
| |
| |
|
|
|
| |
| | | | | | |
| 取代基 | ||||||
| | |
| |
| |
|
|
|
| | | |
| | | ||||
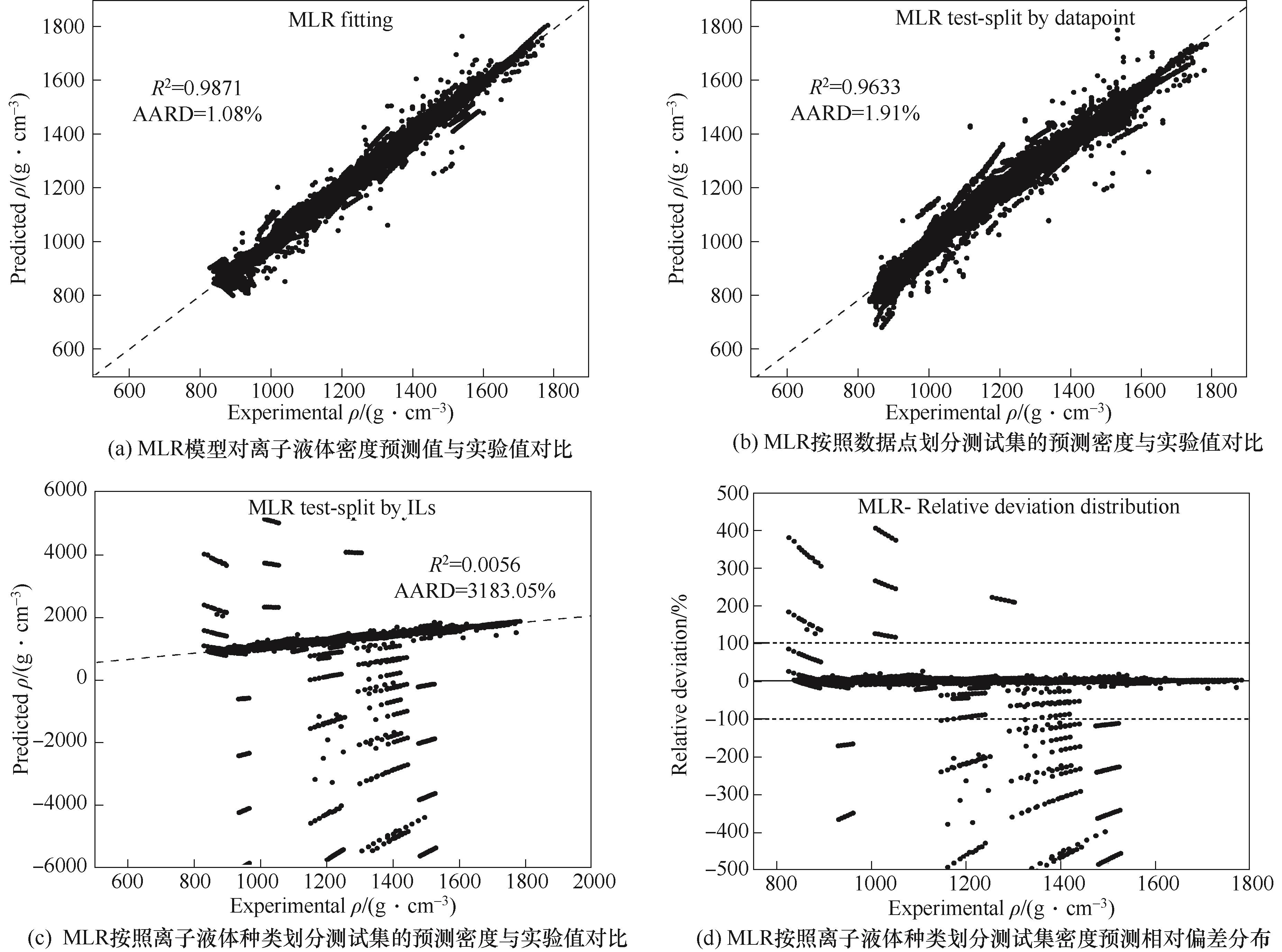
图2 MLR离子液体密度模型及不同测试集划分方式下的测试结果对比
Fig.2 ILs density model based on MLR and test results from different test set partitioning
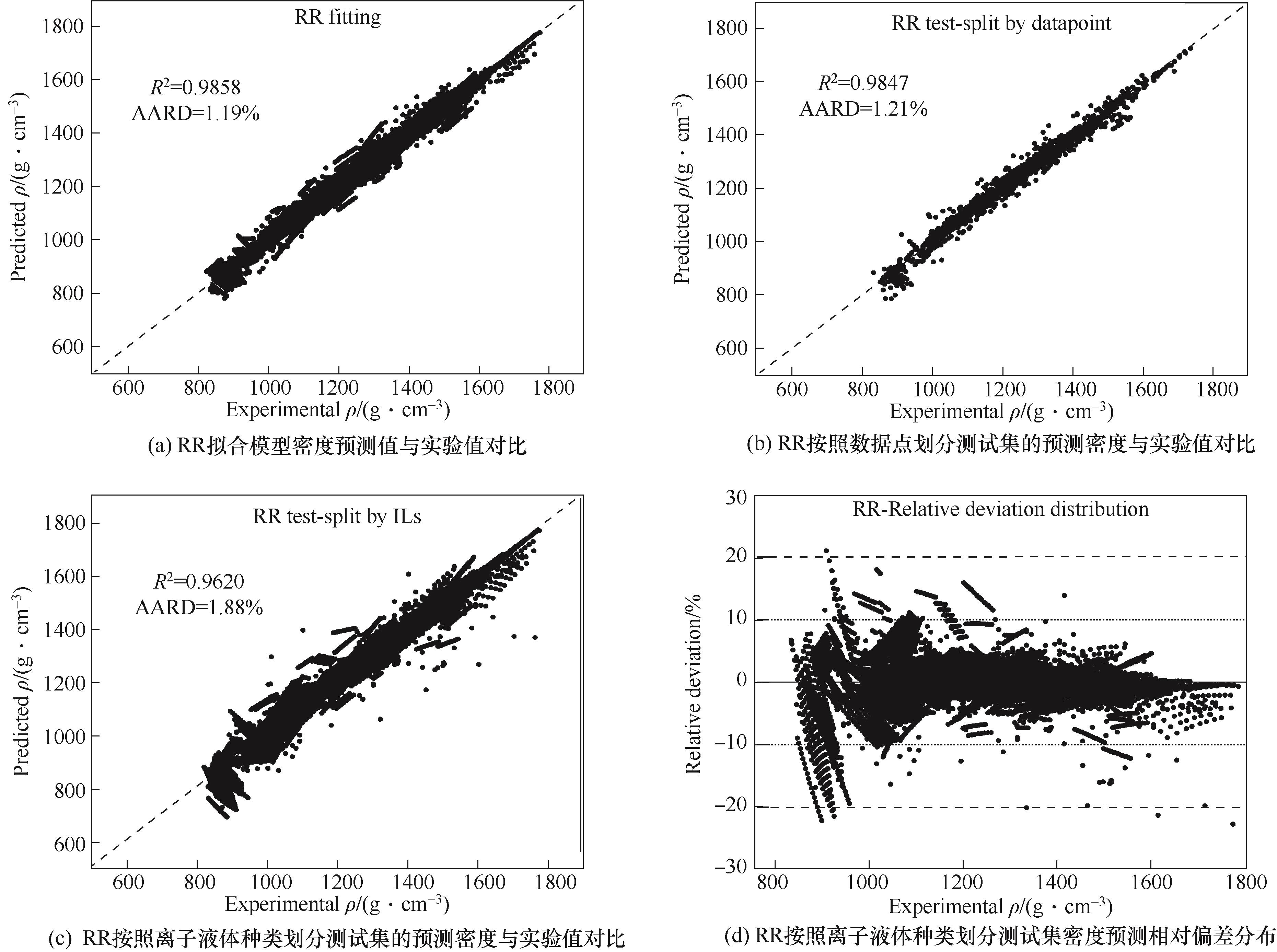
图3 RR拟合密度模型及不同测试集划分方式下的测试结果对比
Fig.3 ILs density model fitted by RR and test results from different test set partitioning
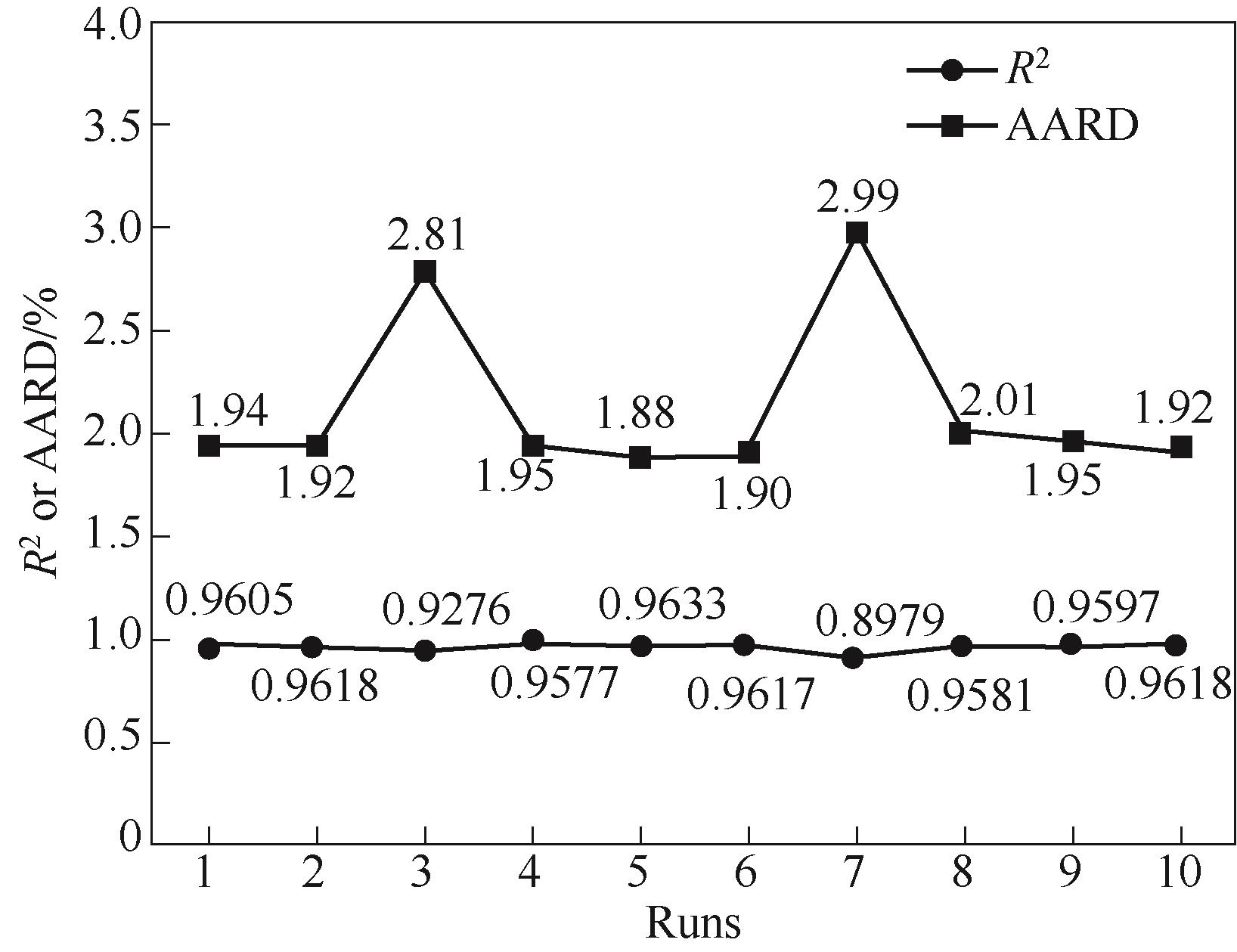
图4 RR多次十折交叉验证测试结果
Fig.4 10 times 10-fold cross-validation test results using RR

图5 基团涉及分子个数对模型预测性能的影响
Fig.5 Effect of the group occurrence threshold (number of ILs containing the group in the dataset) on the prediction accuracy of the resultant model
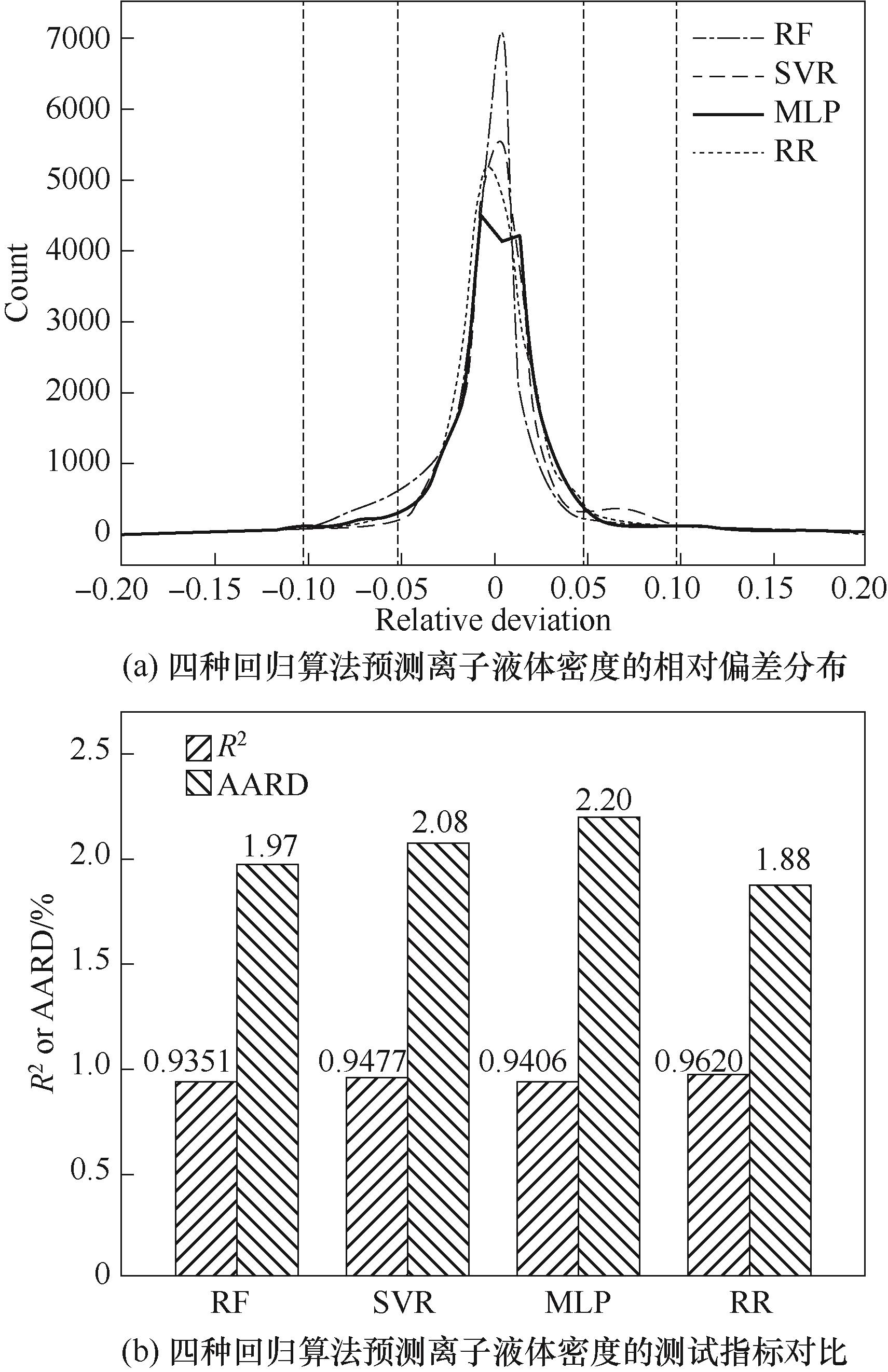
图6 基于RF、SVR、MLP、RR的模型预测性能对比
Fig.6 Prediction performances of models based on RF, SVR, MLP, and RR
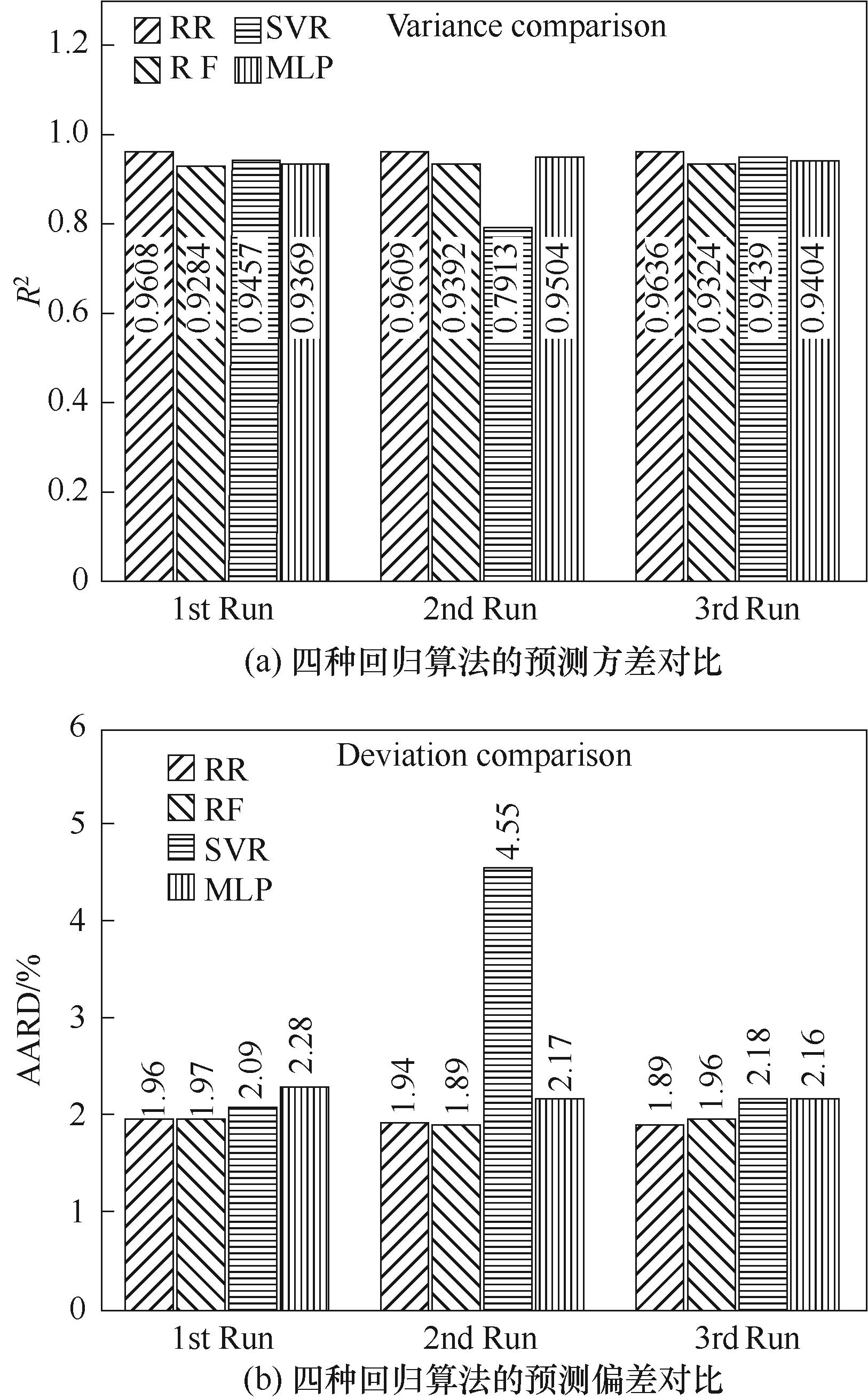
图7 基于额外三次数据划分的算法预测性能对比
Fig.7 Comparison of prediction accuracy of algorithms based on three additional data partitioning
| 基团 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) | 基团 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) |
|---|---|---|---|---|---|---|---|
| [FAP] | 1332.5510 | 35.9926 | -297.6490 | [Br] | 421.2706 | -70.5659 | 1194.5501 |
| [OH] | 315.0302 | -16.4716 | 152.1414 | CH2 | -495.9480 | -139.2680 | 50.2011 |
| [C2H5N] | 363.5765 | -17.0365 | -39.2012 | [N(CN)2] | 534.9675 | 49.3305 | 165.9673 |
| [Quin] | 233.9771 | 141.8892 | 118.2426 | [BOB] | 691.3112 | 141.2362 | 49.9660 |
| [PF6] | 1025.8120 | 86.8174 | -211.2030 | [C(CN)3] | 537.7315 | 20.2244 | 119.5993 |
| [DMP] | 417.2392 | 242.7438 | 98.0166 | [CF3SO3] | 845.8750 | 46.5201 | 1.8886 |
| [PiP] | 445.7565 | 59.1371 | -80.2106 | [CH3(OC2H4)2SO4] | 292.3812 | 261.2657 | 232.6971 |
| [MPyr] | 260.2797 | 213.4264 | 274.2988 | [C6H13P] | 259.4138 | 242.9847 | 456.1185 |
| ACCH2 | -113.2020 | 126.8616 | 37.4342 | CH3O | 174.0913 | -12.3810 | -54.9934 |
| [BET] | 327.4982 | 33.2317 | 111.1289 | CH3COO | 373.9178 | 52.0520 | 327.4936 |
| CH2CO | 28.1721 | 24.4682 | 7.7589 | CH2CN | 309.8592 | 16.7353 | -102.7530 |
| CH2CH | 59.8125 | -64.3985 | -51.3387 | [C4H9N] | 315.9860 | 26.3907 | 88.25078 |
| CH | -356.1550 | 91.7429 | 96.8151 | [NO3] | 367.7095 | 245.1441 | 203.2269 |
| [C2H5P] | 60.7344 | 152.7399 | 240.5752 | ACH | 103.9828 | 95.4698 | -20.8510 |
| [OAc] | 494.5046 | 181.0926 | 177.4210 | [Pyr] | 893.3338 | 88.8546 | -34.8107 |
| [C8H17SO4] | 637.8334 | 25.0786 | 1.8104 | [Tf2N] | 1116.4811 | 146.3694 | -306.3093 |
| [MIm] | 628.0468 | 109.3070 | -259.9160 | [C4F9SO3] | 707.6985 | 230.8441 | 90.8674 |
| CH2O | -181.159 | 108.1054 | 135.9814 | [MMor] | 398.3023 | 92.8417 | -27.4225 |
| CH2COO | -46.3322 | 492.7926 | 276.7435 | CH3 | 356.7834 | -117.3490 | -334.1902 |
| [C8H17P] | 4.4335 | 332.7480 | 137.4351 | [BF4] | 846.4428 | 55.7841 | -130.6170 |
| [Mpy] | 468.9210 | 45.9561 | 12.96739 | [CH3SO4] | 918.2557 | 29.3748 | -202.5350 |
| [Cl] | 975.4551 | 42.8225 | 324.4328 | COOH | 240.8606 | 69.5928 | 65.7629 |
| [SCN] | 565.8685 | -1.6690 | 98.4710 | [Py] | 1032.1431 | 65.0960 | -98.2731 |
| [TOS] | 312.0031 | 286.1815 | 198.6424 | [Im] | 1378.9090 | 170.9318 | -64.9755 |
| [C8H17N] | 129.2648 | 203.1364 | 190.9869 | CH=CH | -50.0497 | -5.9144 | 4.0919 |
| [CH3N] | 212.9291 | 193.4286 | 421.8956 | [C4H9P] | 120.4446 | 13.6882 | 294.3852 |
| [TFA] | 648.9382 | 157.5455 | 11.9933 | [C2H5SO4] | 690.0060 | 14.1393 | 70.6529 |
| [DEP] | 507.8918 | 19.4882 | 199.4548 | [B(CN)4] | 511.4053 | 50.7658 | 103.6770 |
| [CH3SO3] | 636.4792 | 26.6501 | 120.5593 | [I] | 752.8853 | 208.6602 | 49.0845 |
| AC | -210.4530 | -431.0870 | -457.7710 | CHO | -10.0741 | 31.4214 | 24.6816 |
| [DBP] | 241.7651 | 241.6314 | 237.1266 | [Lac] | 534.2245 | 71.8367 | 118.6878 |
表A1 RR拟合的基团贡献参数
Table A1 Group contribution parameters of the obtained RR model
| 基团 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) | 基团 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) |
|---|---|---|---|---|---|---|---|
| [FAP] | 1332.5510 | 35.9926 | -297.6490 | [Br] | 421.2706 | -70.5659 | 1194.5501 |
| [OH] | 315.0302 | -16.4716 | 152.1414 | CH2 | -495.9480 | -139.2680 | 50.2011 |
| [C2H5N] | 363.5765 | -17.0365 | -39.2012 | [N(CN)2] | 534.9675 | 49.3305 | 165.9673 |
| [Quin] | 233.9771 | 141.8892 | 118.2426 | [BOB] | 691.3112 | 141.2362 | 49.9660 |
| [PF6] | 1025.8120 | 86.8174 | -211.2030 | [C(CN)3] | 537.7315 | 20.2244 | 119.5993 |
| [DMP] | 417.2392 | 242.7438 | 98.0166 | [CF3SO3] | 845.8750 | 46.5201 | 1.8886 |
| [PiP] | 445.7565 | 59.1371 | -80.2106 | [CH3(OC2H4)2SO4] | 292.3812 | 261.2657 | 232.6971 |
| [MPyr] | 260.2797 | 213.4264 | 274.2988 | [C6H13P] | 259.4138 | 242.9847 | 456.1185 |
| ACCH2 | -113.2020 | 126.8616 | 37.4342 | CH3O | 174.0913 | -12.3810 | -54.9934 |
| [BET] | 327.4982 | 33.2317 | 111.1289 | CH3COO | 373.9178 | 52.0520 | 327.4936 |
| CH2CO | 28.1721 | 24.4682 | 7.7589 | CH2CN | 309.8592 | 16.7353 | -102.7530 |
| CH2CH | 59.8125 | -64.3985 | -51.3387 | [C4H9N] | 315.9860 | 26.3907 | 88.25078 |
| CH | -356.1550 | 91.7429 | 96.8151 | [NO3] | 367.7095 | 245.1441 | 203.2269 |
| [C2H5P] | 60.7344 | 152.7399 | 240.5752 | ACH | 103.9828 | 95.4698 | -20.8510 |
| [OAc] | 494.5046 | 181.0926 | 177.4210 | [Pyr] | 893.3338 | 88.8546 | -34.8107 |
| [C8H17SO4] | 637.8334 | 25.0786 | 1.8104 | [Tf2N] | 1116.4811 | 146.3694 | -306.3093 |
| [MIm] | 628.0468 | 109.3070 | -259.9160 | [C4F9SO3] | 707.6985 | 230.8441 | 90.8674 |
| CH2O | -181.159 | 108.1054 | 135.9814 | [MMor] | 398.3023 | 92.8417 | -27.4225 |
| CH2COO | -46.3322 | 492.7926 | 276.7435 | CH3 | 356.7834 | -117.3490 | -334.1902 |
| [C8H17P] | 4.4335 | 332.7480 | 137.4351 | [BF4] | 846.4428 | 55.7841 | -130.6170 |
| [Mpy] | 468.9210 | 45.9561 | 12.96739 | [CH3SO4] | 918.2557 | 29.3748 | -202.5350 |
| [Cl] | 975.4551 | 42.8225 | 324.4328 | COOH | 240.8606 | 69.5928 | 65.7629 |
| [SCN] | 565.8685 | -1.6690 | 98.4710 | [Py] | 1032.1431 | 65.0960 | -98.2731 |
| [TOS] | 312.0031 | 286.1815 | 198.6424 | [Im] | 1378.9090 | 170.9318 | -64.9755 |
| [C8H17N] | 129.2648 | 203.1364 | 190.9869 | CH=CH | -50.0497 | -5.9144 | 4.0919 |
| [CH3N] | 212.9291 | 193.4286 | 421.8956 | [C4H9P] | 120.4446 | 13.6882 | 294.3852 |
| [TFA] | 648.9382 | 157.5455 | 11.9933 | [C2H5SO4] | 690.0060 | 14.1393 | 70.6529 |
| [DEP] | 507.8918 | 19.4882 | 199.4548 | [B(CN)4] | 511.4053 | 50.7658 | 103.6770 |
| [CH3SO3] | 636.4792 | 26.6501 | 120.5593 | [I] | 752.8853 | 208.6602 | 49.0845 |
| AC | -210.4530 | -431.0870 | -457.7710 | CHO | -10.0741 | 31.4214 | 24.6816 |
| [DBP] | 241.7651 | 241.6314 | 237.1266 | [Lac] | 534.2245 | 71.8367 | 118.6878 |
| 基团种类 | 个数 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) |
|---|---|---|---|---|
| [MPyr] | 1 | 260.2797 | 213.4264 | 274.2988 |
| [Tf2N] | 1 | 1116.4811 | 146.3694 | -306.3093 |
| CH2CN | 1 | 309.8592 | 16.7353 | -102.7530 |
表A2 [ACNMPyr][Tf2N]基团划分及基团贡献参数
Table A2 Group fragmentation of [ACNMPyr][Tf2N] and the corresponding contribution parameters
| 基团种类 | 个数 | ai /(g·cm-3) | bi /(g·cm-3) | ci /(g·cm-3) |
|---|---|---|---|---|
| [MPyr] | 1 | 260.2797 | 213.4264 | 274.2988 |
| [Tf2N] | 1 | 1116.4811 | 146.3694 | -306.3093 |
| CH2CN | 1 | 309.8592 | 16.7353 | -102.7530 |
| 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 |
|---|---|---|---|---|---|---|---|
| [FAP] | 20 | [MIm] | 94 | CH2 | 5137 | [MMor] | 24 |
| [OH] | 83 | CH2O | 264 | [N(CN)2] | 76 | CH3 | 1842 |
| [C2H5N] | 40 | CH2COO | 34 | [BOB] | 9 | [BF4] | 66 |
| [Quin] | 4 | [C8H17P] | 15 | [C(CN)3] | 7 | [CH3SO4] | 32 |
| [PF6] | 28 | [Mpy] | 21 | [CF3SO3] | 31 | COOH | 10 |
| [DMP] | 10 | [Cl] | 56 | [CH3(OC2H4)2SO4] | 4 | [Py] | 124 |
| [PiP] | 50 | [SCN] | 29 | [C6H13P] | 24 | [Im] | 498 |
| [MPyr] | 16 | [TOS] | 8 | CH3O | 62 | CH=CH | 6 |
| ACCH2 | 15 | [C8H17N] | 10 | CH3COO | 19 | [C4H9P] | 36 |
| [BET] | 16 | [CH3N] | 124 | CH2CN | 57 | [C2H5SO4] | 18 |
| CH2CO | 2 | [TFA] | 22 | [C4H9N] | 17 | [B(CN)4] | 12 |
| CH2CH | 36 | [DEP] | 7 | [NO3] | 10 | [I] | 4 |
| CH | 115 | [CH3SO3] | 23 | ACH | 283 | CHO | 24 |
| [C2H5P] | 25 | AC | 43 | [Pyr] | 54 | [Lac] | 11 |
| [OAc] | 7 | [DBP] | 10 | [Tf2N] | 503 | ||
| [C8H17SO4] | 2 | [Br] | 40 | [C4F9SO3] | 11 |
表A3 各基团涉及分子个数
Table A3 Summary of the number of ILs containing each group in the dataset
| 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 | 基团种类 | 涉及分子个数 |
|---|---|---|---|---|---|---|---|
| [FAP] | 20 | [MIm] | 94 | CH2 | 5137 | [MMor] | 24 |
| [OH] | 83 | CH2O | 264 | [N(CN)2] | 76 | CH3 | 1842 |
| [C2H5N] | 40 | CH2COO | 34 | [BOB] | 9 | [BF4] | 66 |
| [Quin] | 4 | [C8H17P] | 15 | [C(CN)3] | 7 | [CH3SO4] | 32 |
| [PF6] | 28 | [Mpy] | 21 | [CF3SO3] | 31 | COOH | 10 |
| [DMP] | 10 | [Cl] | 56 | [CH3(OC2H4)2SO4] | 4 | [Py] | 124 |
| [PiP] | 50 | [SCN] | 29 | [C6H13P] | 24 | [Im] | 498 |
| [MPyr] | 16 | [TOS] | 8 | CH3O | 62 | CH=CH | 6 |
| ACCH2 | 15 | [C8H17N] | 10 | CH3COO | 19 | [C4H9P] | 36 |
| [BET] | 16 | [CH3N] | 124 | CH2CN | 57 | [C2H5SO4] | 18 |
| CH2CO | 2 | [TFA] | 22 | [C4H9N] | 17 | [B(CN)4] | 12 |
| CH2CH | 36 | [DEP] | 7 | [NO3] | 10 | [I] | 4 |
| CH | 115 | [CH3SO3] | 23 | ACH | 283 | CHO | 24 |
| [C2H5P] | 25 | AC | 43 | [Pyr] | 54 | [Lac] | 11 |
| [OAc] | 7 | [DBP] | 10 | [Tf2N] | 503 | ||
| [C8H17SO4] | 2 | [Br] | 40 | [C4F9SO3] | 11 |
| 1 | Shen J, Nicolaou C A. Molecular property prediction: recent trends in the era of artificial intelligence[J]. Drug Discovery Today: Technologies, 2019, 32/33: 29-36. |
| 2 | Velez C, Acevedo O. Simulation of deep eutectic solvents: progress to promises[J]. WIREs Computational Molecular Science, 2022, 12(4): e1598. |
| 3 | López-López E, Bajorath J, Medina-Franco J L. Informatics for chemistry, biology, and biomedical sciences[J]. Journal of Chemical Information and Modeling, 2021, 61(1): 26-35. |
| 4 | Vermeire F H, Chung Y, Green W H. Predicting solubility limits of organic solutes for a wide range of solvents and temperatures[J]. Journal of the American Chemical Society, 2022, 144(24): 10785-10797. |
| 5 | Tan T, Cheng H Y, Chen G Z, et al. Prediction of infinite-dilution activity coefficients with neural collaborative filtering[J]. AIChE Journal, 2022, 68(9): e17789. |
| 6 | Muratov E N, Bajorath J, Sheridan R P, et al. QSAR without borders[J]. Chemical Society Reviews, 2020, 49(11): 3525-3564. |
| 7 | Stärk H, Beaini D, Corso G, et al. 3D infomax improves GNNs for molecular property prediction[EB/OL]. 2021, arXiv: 2110.04126[cs.LG]. . |
| 8 | Chen D, Gao K F, Nguyen D D, et al. Algebraic graph-assisted bidirectional transformers for molecular property prediction[J]. Nature Communications, 2021, 12(1): 3521. |
| 9 | 桂成敏, 朱瑞松, 张傑, 等. 离子液体气体干燥技术的研究进展[J]. 化工学报, 2020, 71(1): 92-105. |
| Gui C M, Zhu R S, Zhang J, et al. Progress on ionic liquids for gas drying[J]. CIESC Journal, 2020, 71(1): 92-105. | |
| 10 | Peng D L, Zhang J N, Cheng H Y, et al. Computer-aided ionic liquid design for separation processes based on group contribution method and COSMO-SAC model[J]. Chemical Engineering Science, 2017, 159: 58-68. |
| 11 | Yan F Y, He W S, Jia Q Z, et al. Prediction of ionic liquids viscosity at variable temperatures and pressures[J]. Chemical Engineering Science, 2018, 184: 134-140. |
| 12 | Chen G Z, Song Z, Qi Z W, et al. Neural recommender system for the activity coefficient prediction and UNIFAC model extension of ionic liquid-solute systems[J]. AIChE Journal, 2021, 67(4): e17171. |
| 13 | Gardas R L, Coutinho J A P. Group contribution methods for the prediction of thermophysical and transport properties of ionic liquids[J]. AIChE Journal, 2009, 55(5): 1274-1290. |
| 14 | Sepehri B. A review on created QSPR models for predicting ionic liquids properties and their reliability from chemometric point of view[J]. Journal of Molecular Liquids, 2020, 297: 112013. |
| 15 | Lei Z G, Dai C N, Wang W, et al. UNIFAC model for ionic liquid-CO2 systems[J]. AIChE Journal, 2014, 60(2): 716-729. |
| 16 | Rybinska-Fryca A, Sosnowska A, Puzyn T. Prediction of dielectric constant of ionic liquids[J]. Journal of Molecular Liquids, 2018, 260: 57-64. |
| 17 | Mellein B R, Scurto A M, Shiflett M B. Gas solubility in ionic liquids[J]. Current Opinion in Green and Sustainable Chemistry, 2021, 28: 100425. |
| 18 | Dong K, Liu X M, Dong H F, et al. Multiscale studies on ionic liquids[J]. Chemical Reviews, 2017, 117(10): 6636-6695. |
| 19 | Paduszyński K, Domańska U. Viscosity of ionic liquids: an extensive database and a new group contribution model based on a feed-forward artificial neural network[J]. Journal of Chemical Information and Modeling, 2014, 54(5): 1311-1324. |
| 20 | Makarov D M, Fadeeva Y A, Shmukler L E, et al. Beware of proper validation of models for ionic Liquids![J]. Journal of Molecular Liquids, 2021, 344: 117722. |
| 21 | Koutsoukos S, Philippi F, Malaret F, et al. A review on machine learning algorithms for the ionic liquid chemical space[J]. Chemical Science, 2021, 12(20): 6820-6843. |
| 22 | Gardas R L, Coutinho J A P. Extension of the Ye and Shreeve group contribution method for density estimation of ionic liquids in a wide range of temperatures and pressures[J]. Fluid Phase Equilibria, 2008, 263(1): 26-32. |
| 23 | Lazzús J A, Pulgar- Villarroel G. A group contribution method to estimate the viscosity of ionic liquids at different temperatures[J]. Journal of Molecular Liquids, 2015, 209: 161-168. |
| 24 | Taherifard H, Raeissi S. Estimation of the densities of ionic liquids using a group contribution method[J]. Journal of Chemical & Engineering Data, 2016, 61(12): 4031-4038. |
| 25 | Chen Y Q, Kontogeorgis G M, Woodley J M. Group contribution based estimation method for properties of ionic liquids[J]. Industrial & Engineering Chemistry Research, 2019, 58(10): 4277-4292. |
| 26 | Paduszyński K. Extensive databases and group contribution QSPRs of ionic liquids properties (1): Density[J]. Industrial & Engineering Chemistry Research, 2019, 58(13): 5322-5338. |
| 27 | Paduszyński K. Extensive databases and group contribution QSPRs of ionic liquids properties (2): Viscosity[J]. Industrial & Engineering Chemistry Research, 2019, 58(36): 17049-17066. |
| 28 | Paduszyński K. Extensive databases and group contribution QSPRs of ionic liquid properties (3): Surface tension[J]. Industrial & Engineering Chemistry Research, 2021, 60(15): 5705-5720. |
| 29 | Alshehri A S, Tula A K, You F, et al. Next generation pure component property estimation models: with and without machine learning techniques[J]. AIChE Journal, 2022, 68(6): e17469. |
| 30 | Alshehri A S, Gani R, You F Q. Deep learning and knowledge-based methods for computer-aided molecular design—toward a unified approach: state-of-the-art and future directions[J]. Computers & Chemical Engineering, 2020, 141: 107005. |
| 31 | Kailkhura B, Gallagher B, Kim S, et al. Reliable and explainable machine-learning methods for accelerated material discovery[J]. Npj Computational Materials, 2019, 5(1): 108. |
| 32 | Esmaeili-Jaghdan Z, Shariati A, Nikou M R K. A hybrid smart modeling approach for estimation of pure ionic liquids viscosity[J]. Journal of Molecular Liquids, 2016, 222: 14-27. |
| 33 | Song Z, Shi H W, Zhang X, et al. Prediction of CO2 solubility in ionic liquids using machine learning methods[J]. Chemical Engineering Science, 2020, 223: 115752. |
| 34 | Kazakov A F, Magee J W, Chirico R D, et al. Ionic Liquids Database - ILThermo (v 2.0)[DB/OL]. NIST, 2013[2022-07-23]. . |
| 35 | Müller S. Flexible heuristic algorithm for automatic molecule fragmentation: application to the UNIFAC group contribution model[J]. Journal of Cheminformatics, 2019, 11(1): 57. |
| 36 | Qiao Y, Ma Y G, Huo Y, et al. A group contribution method to estimate the densities of ionic liquids[J]. The Journal of Chemical Thermodynamics, 2010, 42(7): 852-855. |
| 37 | 熊焰, 丁靖, 虞大红, 等. 离子液体热物理性质与相行为预测的基团贡献法[J]. 化工学报, 2012, 63(3): 667-676. |
| Xiong Y, Ding J, Yu D H, et al. Group contribution methods for prediction of thermophysical properties and phase behavior of ionic liquids[J]. CIESC Journal, 2012, 63(3): 667-676. | |
| 38 | Zhou Z H. Machine Learning [M]. Singapore: Springer, 2021. |
| 39 | Leeuwenberg A M, Smeden M V, Langendijk J A, et al. Comparing methods addressing multi-collinearity when developing prediction models[EB/OL]. 2021, arXiv: 2101.01603[stat.ME]. . |
| 40 | Krstajic D, Buturovic L J, Leahy D E, et al. Cross-validation pitfalls when selecting and assessing regression and classification models[J]. Journal of Cheminformatics, 2014, 6(1): 10. |
| 41 | Zanotti C, Rotiroti M, Sterlacchini S, et al. Choosing between linear and nonlinear models and avoiding overfitting for short and long term groundwater level forecasting in a linear system[J]. Journal of Hydrology, 2019, 578: 124015. |
| [1] | 张龙, 宋孟杰, 邵苛苛, 张旋, 沈俊, 高润淼, 甄泽康, 江正勇. 管翅式换热器迎风侧翅片末端霜层生长模拟研究[J]. 化工学报, 2023, 74(S1): 179-182. |
| [2] | 王琪, 张斌, 张晓昕, 武虎建, 战海涛, 王涛. 氯铝酸-三乙胺离子液体/P2O5催化合成伊索克酸和2-乙基蒽醌[J]. 化工学报, 2023, 74(S1): 245-249. |
| [3] | 宋嘉豪, 王文. 斯特林发动机与高温热管耦合运行特性研究[J]. 化工学报, 2023, 74(S1): 287-294. |
| [4] | 晁京伟, 许嘉兴, 李廷贤. 基于无管束蒸发换热强化策略的吸附热池的供热性能研究[J]. 化工学报, 2023, 74(S1): 302-310. |
| [5] | 连梦雅, 谈莹莹, 王林, 陈枫, 曹艺飞. 地下水预热新风一体化热泵空调系统制热性能研究[J]. 化工学报, 2023, 74(S1): 311-319. |
| [6] | 金正浩, 封立杰, 李舒宏. 氨水溶液交叉型再吸收式热泵的能量及 分析[J]. 化工学报, 2023, 74(S1): 53-63. 分析[J]. 化工学报, 2023, 74(S1): 53-63. |
| [7] | 米泽豪, 花儿. 基于DFT和COSMO-RS理论研究多元胺型离子液体吸收SO2气体[J]. 化工学报, 2023, 74(9): 3681-3696. |
| [8] | 车睿敏, 郑文秋, 王小宇, 李鑫, 许凤. 基于离子液体的纤维素均相加工研究进展[J]. 化工学报, 2023, 74(9): 3615-3627. |
| [9] | 陆俊凤, 孙怀宇, 王艳磊, 何宏艳. 离子液体界面极化及其调控氢键性质的分子机理[J]. 化工学报, 2023, 74(9): 3665-3680. |
| [10] | 郑佳丽, 李志会, 赵新强, 王延吉. 离子液体催化合成2-氰基呋喃反应动力学研究[J]. 化工学报, 2023, 74(9): 3708-3715. |
| [11] | 李科, 文键, 忻碧平. 耦合蒸气冷却屏的真空多层绝热结构对液氢储罐自增压过程的影响机制研究[J]. 化工学报, 2023, 74(9): 3786-3796. |
| [12] | 王浩, 王振雷. 基于自适应谱方法的裂解炉烧焦模型化简策略[J]. 化工学报, 2023, 74(9): 3855-3864. |
| [13] | 宋明昊, 赵霏, 刘淑晴, 李国选, 杨声, 雷志刚. 离子液体脱除模拟油中挥发酚的多尺度模拟与研究[J]. 化工学报, 2023, 74(9): 3654-3664. |
| [14] | 曹跃, 余冲, 李智, 杨明磊. 工业数据驱动的加氢裂化装置多工况切换过渡状态检测[J]. 化工学报, 2023, 74(9): 3841-3854. |
| [15] | 杨绍旗, 赵淑蘅, 陈伦刚, 王晨光, 胡建军, 周清, 马隆龙. Raney镍-质子型离子液体体系催化木质素平台分子加氢脱氧制备烷烃[J]. 化工学报, 2023, 74(9): 3697-3707. |
| 阅读次数 | ||||||
|
全文 |
|
|||||
|
摘要 |
|
|||||
 京公网安备 11010102001995号
京公网安备 11010102001995号




















